




JVM(Java Virtual Machine)java虚拟机,相比较于JMM而言JVM是一套物理模型,JVM虽然是叫做Java虚拟机但也是独立于于java语言的,总体说JVM只是java用的底层执行引擎,java的class文件才是JVM认识的,java文件JVM无法识别,在编程语言中Scala,Python的Jpython解释器(把python代码解释成java字节码文件放入JVM)这些都用的是JVM,JVM也是java语言跨平台的原因,JVM可以根据平台(windown,os,linux……)编译机器码
一个程序的运行所经历的过程:源代码 -> 编译器 -> class文件 -> JVM -> 机器码 -> 计算机运行
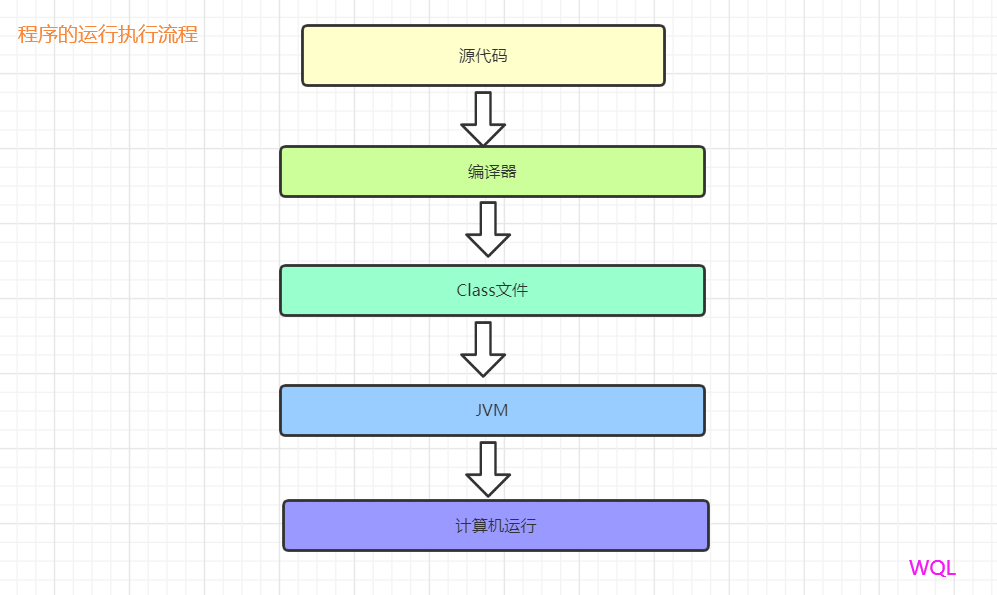
编译器:每种编程语言的由于语法不同,对应的编译器也不一样,但都可以转化成字节码文件供JVM执行
注:在java的final修饰的常量在编译期就分配了空间
一,JVM的组成部分
JVM主要由三部分组成:类加载系统,运行时数据区,执行引擎
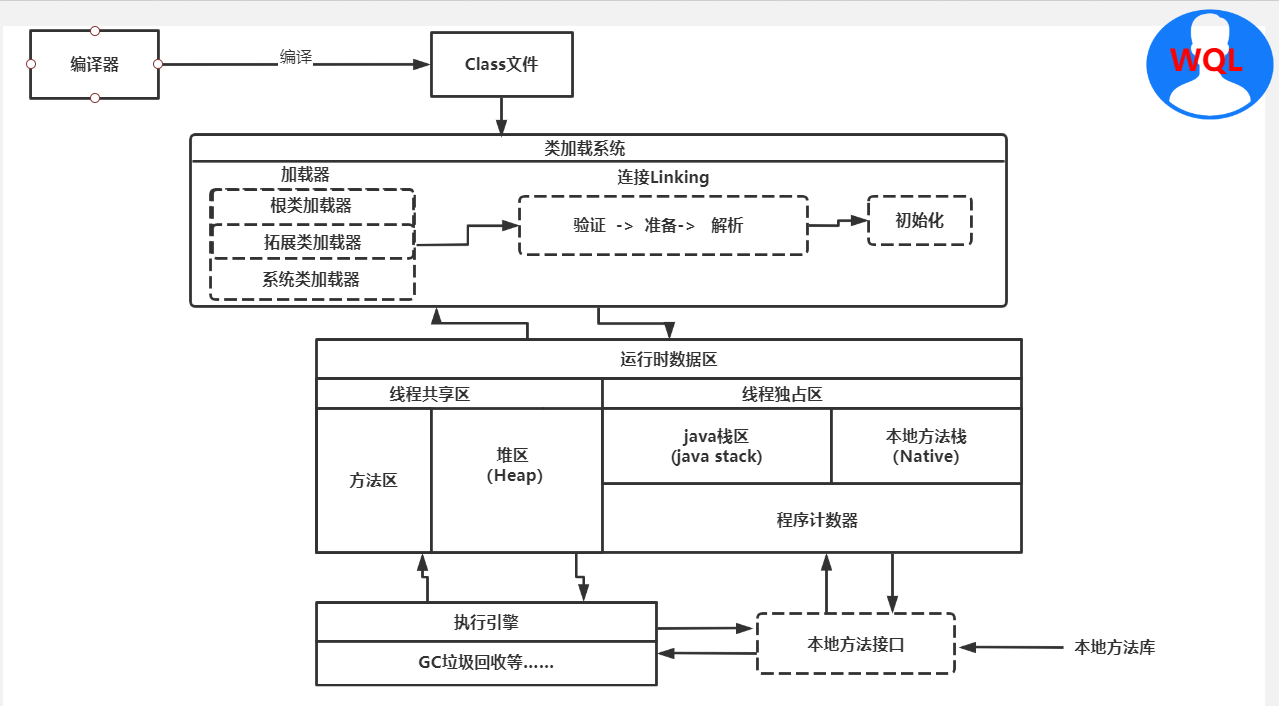
1,类加载系统:把class文件的字节码数据加载到内存,并把这些内容转化成方法区中的运行时数据结构并在此过程中进行验证并对static进行初始
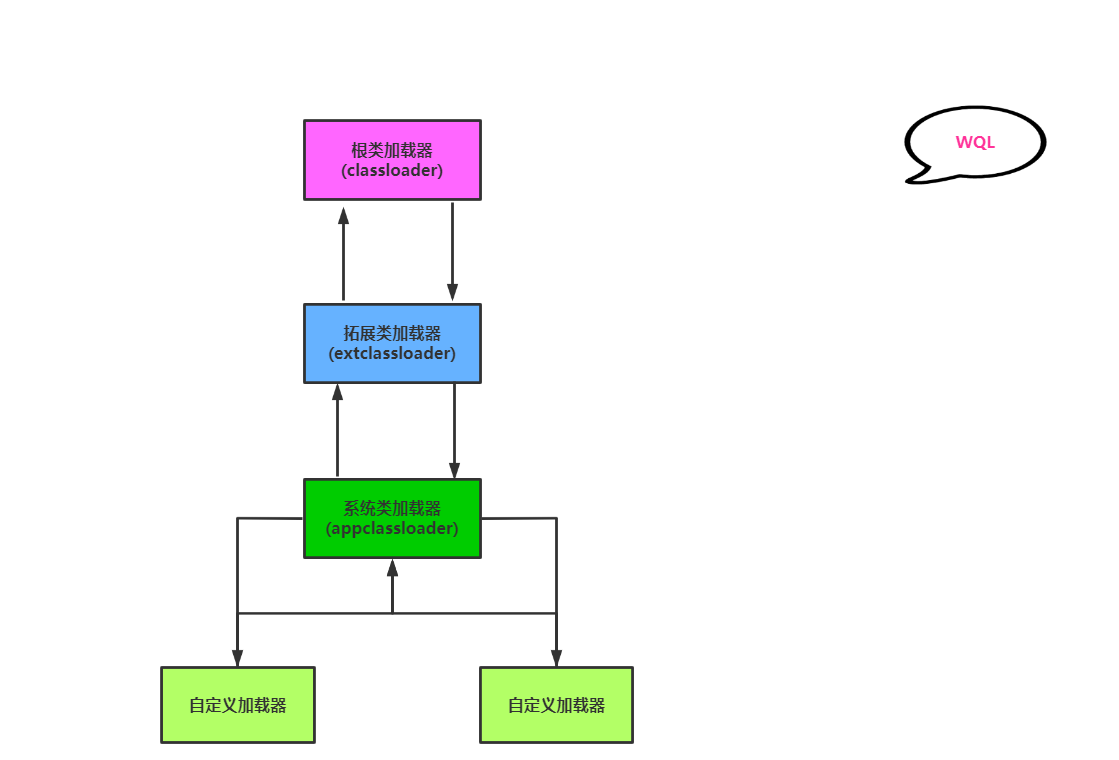
类加载器:主要有三个根类加载器,拓展类加载器,系统类加载器,负责加载运行时数据结构到方法区中,三者出于安全有双亲委派机制和沙箱机制
Linking:验证:读取类信息检查有没有破坏JVM运行的因素,
准备:把start修饰的方法和变量初始化(但赋值是在后面的初始化中)
解析:将类、方法、属性等符号引用解析为直接引用,让写的字符指向一个真正的内存空间(常量池也被自己引用)
初始化:把类属性进行初始进入方法区
2,运行时数据区:数据的存储位置,分为线程共享和线程独占
线程共享:在JVM中只有一个,所有线程共有的一个区域
线程独占:每一个new对象都会开辟一个的自己独有的区域,在JVM有n个独占区
3,执行引擎:JIT编译器:进行机器码的转化,也对代码进行中间优化
GC:垃圾回收器,对堆进行回收清理
4,本地方法库:与本地方法栈结合,本地方法栈主要作用是引入本地库中的方法,本地方法主要是第三方语言编写的如C++,C(java本身无法操作系统,native调用第三方操作系统,如:线程的手动创建和消亡)
二,类加载器
类加载过程:
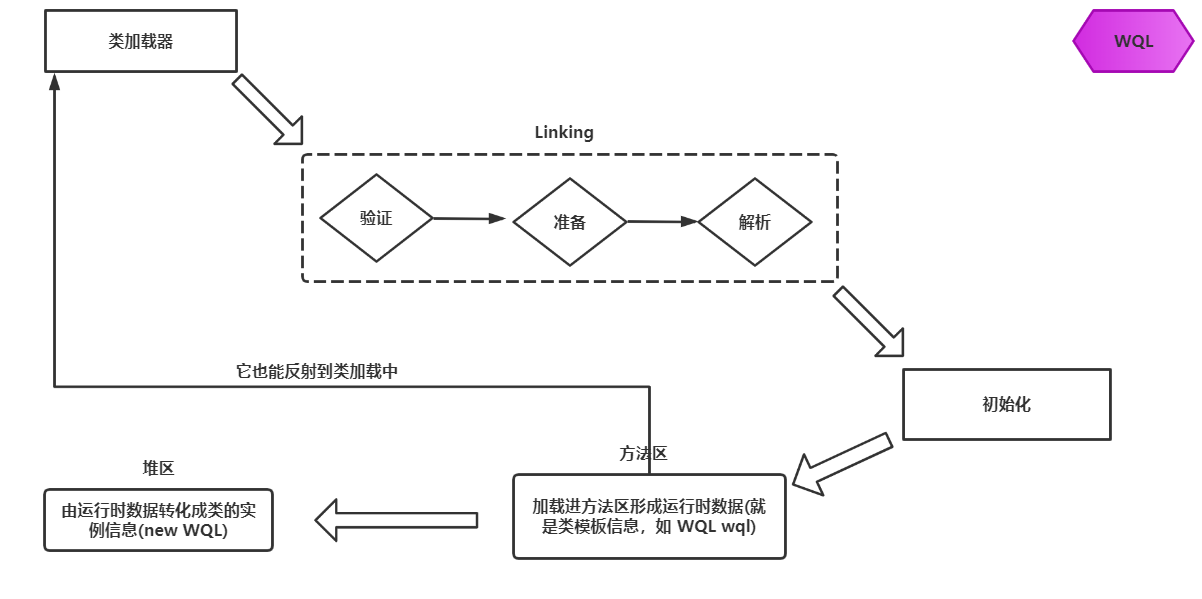

解释上面有
类加载器的种类:
1,根类加载器:负责加载java环境jar包文件,主要是rt.jar包,在rt.jar主要有java和javax,java文件中有常用类(根加载器是C语言实现)
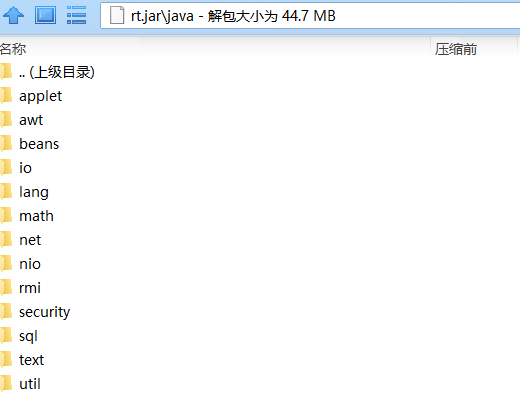
2,拓展类加载器:负责加载java的补充类和主要添加类,主要加载jre/lib/ext的文件,
3,系统类加载器:负责加载自定义类
双亲委派机制:类加载器向上提交加载,当一个自定义类在系统类加载器了,它首先不会自己去加载而是向上交给父加载器(拓展类加载器)判断,然而拓展类加载器自己再交给它的父加载器,如果根加载器这个顶级类加载器加载不出,就向下加载形成一个循环,直到被加载
public static void main(String[] args) {
Object a=new Object();//系统类,读取他的加载器
System.out.println(a.getClass().getClassLoader());//返回null代表他是根加载器,他是C++语言写的
textwq h=new textwq();//自定义类,打印他的加载器类型
System.out.println(h.getClass().getClassLoader());//返回AppClassLoader代表是系统类加载器
System.out.print(h.getClass().getClassLoader().getParent());//返回h类的父加载器拓展加载器}
双亲委派机制的出发的:防止篡改源代码,防止有人替换系统本身的类,当一个被父加载器加载了就不再加载了(具体手段就是沙箱机制)
沙箱机制:java的安全策略,限制资源访问

三,方法区和堆
一,方法区
方法区是在类加载时属于一个中间流转站,类加载把class文件读取到内存,类加载器和Linking转化为运行时数据,加载到方法区中,方法区存储被虚拟机加载的类信息、常量、静态变量,静态代码块,类信息也叫模板给堆new实例对象,方法区内部还静态方法区和常量池,存储static和final修饰的属性和方法,在java1.8之前方法区是堆区的永久带,在1.8之后为了方法区脱离堆,形成一个非堆区,用源空间替代永久带
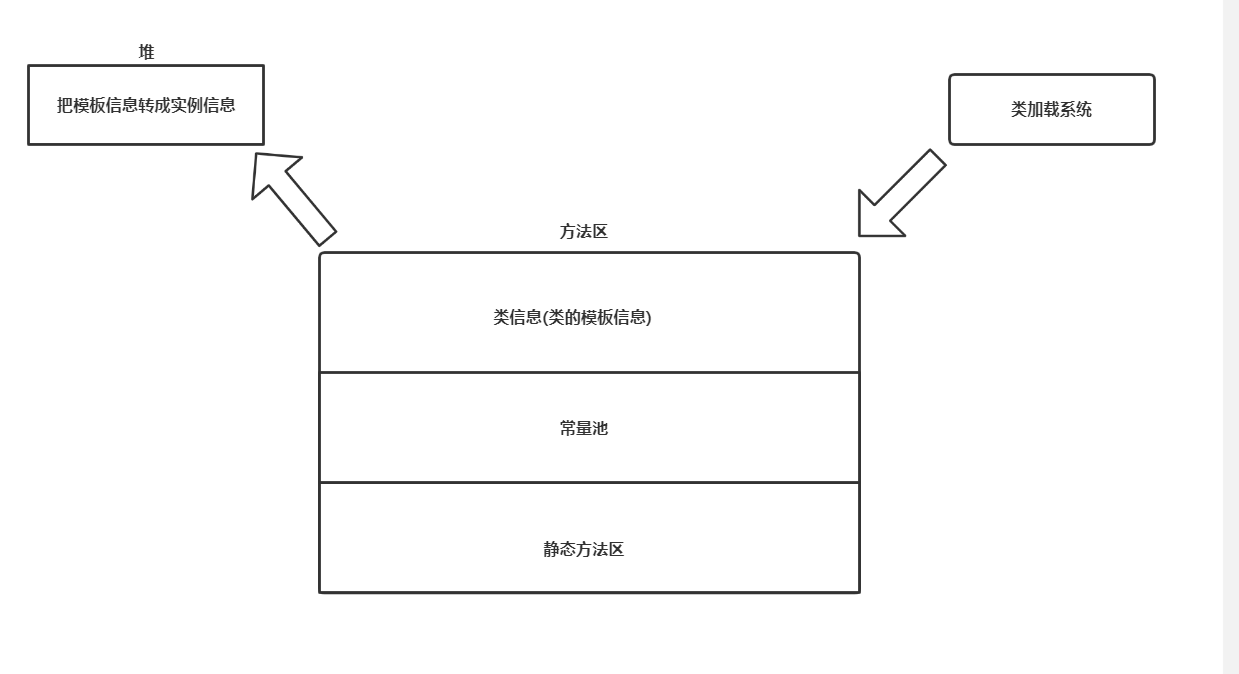
方法区存储内容:
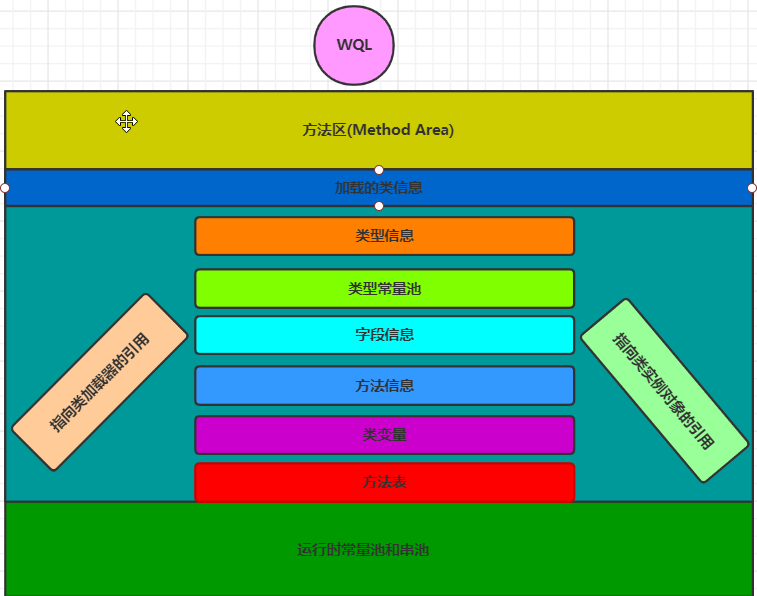

类型信息:
1,类的修饰符
2,类的父类
3,类的接口实现列表
4,类的完整包名
字段信息:
1,字段类型
2,修饰符
3,声明顺序
4,字段名称
方法信息:
1,声明顺序
2,方法名
3,参数列表
4,修饰符
5,方法名
6,返回值类型
7,操作数栈和局部变量表的大小分配
8,异常表
类型常量池:
类型常量池不能和运行时常量池搞混淆,每一个class文件都维护着一个常量池(类型常量池),这个常量池存储着编译期生成的大量字面量和符号引用,在类加载器加载class文件时,这个常量池会被复制进运行时常量池
字面量:在编译期间就可以确定下来的值,如基本数据和String以及它们的包装类,final修饰的变量
符合引用:不同于直接引用,它是写在class文件的引用,类似于前期绑定,它负责对类对象,方法的引用
二,堆
1,堆的内存区块
堆分为三个区带:新生带,老年带,永久带
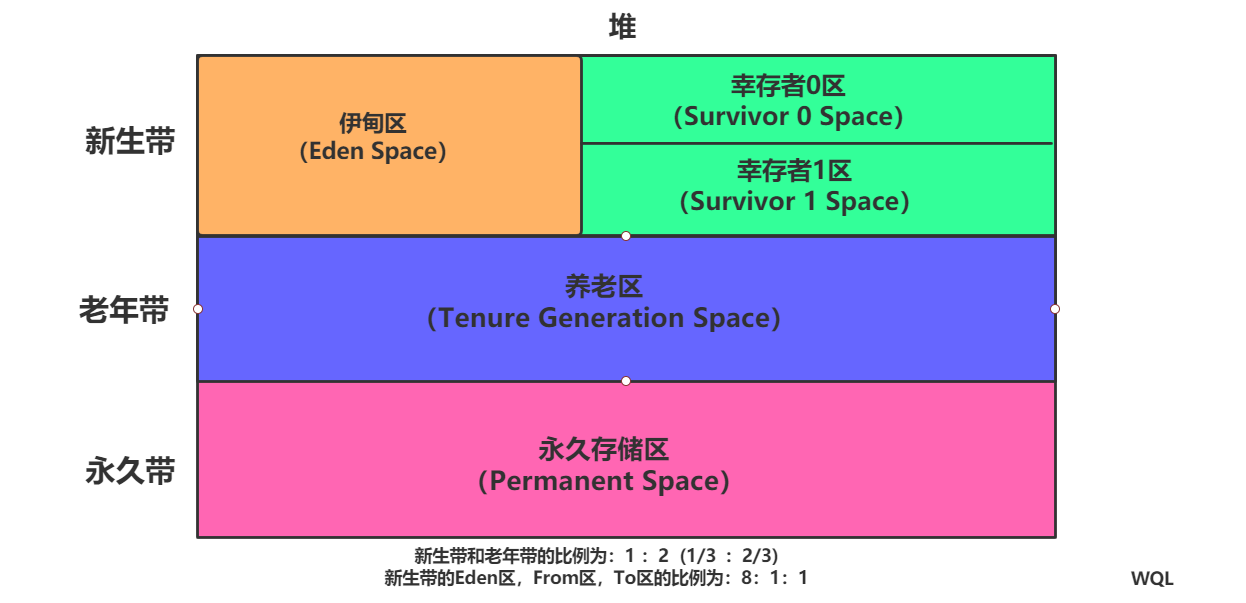
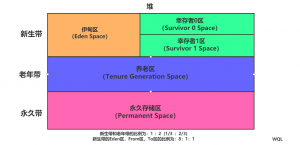
新生区:Eden区,From区,To区,他们在新生带存储比例分别是 8:1:1
堆是GC的主要回收目标,
刚new的对象放在堆中的新生带,新生带的对象每次内存接近设置的临界值时会触发一次GC,新生带的GC会回收95%的对象,没有回收的对象被存在From或者To区(这两个区相当于中间缓冲流转区),假如在新生带GC15次还没有被回收,会被存入老年带
2,堆的参数调整
JVM的调参主要是调堆区的参数
在JVM中堆的内存大小的占系统内存占比:堆的初始大小(Xms)占物理内存的1/64,最大值(Xmx)占物理内存的1/4
堆的主要调优参数:
| 参数名称 | 含义 | 默认值 | |
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 |
|
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 |
辅助参数(如:日志输出):
| -XX:+PrintGC | 输出形式:
[GC 118250K->113543K(130112K), 0.0094143 secs] |
||
| -XX:+PrintGCDetails | 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs] |
||
| -XX:+PrintGCTimeStamps | |||
| -XX:+PrintGC:PrintGCTimeStamps | 可与-XX:+PrintGC -XX:+PrintGCDetails混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] |
||
| -XX:+PrintGCApplicationStoppedTime | 打印垃圾回收期间程序暂停的时间.可与上面混合使用 | 输出形式:Total time for which application threads were stopped: 0.0468229 seconds | |
| -XX:+PrintGCApplicationConcurrentTime | 打印每次垃圾回收前,程序未中断的执行时间.可与上面混合使用 | 输出形式:Application time: 0.5291524 seconds | |
| -XX:+PrintHeapAtGC | 打印GC前后的详细堆栈信息 | ||
| -Xloggc:filename | 把相关日志信息记录到文件以便分析. 与上面几个配合使用 |
||
| -XX:+PrintClassHistogram | garbage collects before printing the histogram. | ||
| -XX:+PrintTLAB | 查看TLAB空间的使用情况 | ||
| XX:+PrintTenuringDistribution | 查看每次minor GC后新的存活周期的阈值 | Desired survivor size 1048576 bytes, new threshold 7 (max 15) new threshold 7即标识新的存活周期的阈值为7。 |
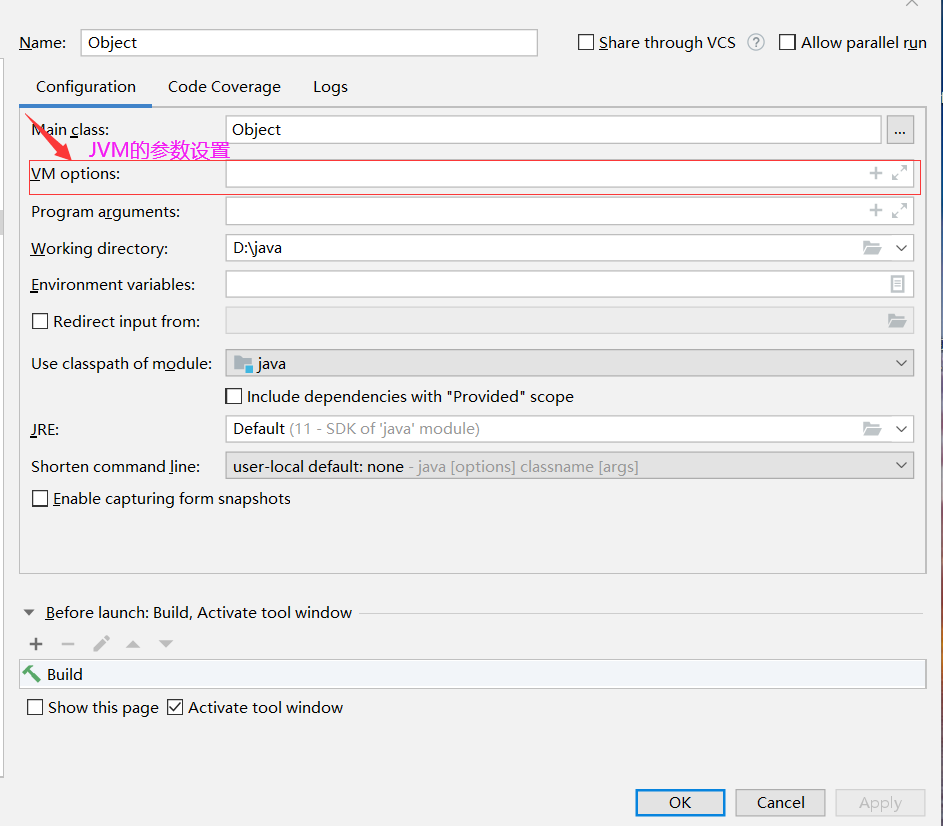
参数调优在IDEA的run下的Edit Configurations,点击打开
打印堆信息:
public static void main(String[] args) {
//Runtime类可以访问环境属性
Runtime a= Runtime.getRuntime();//获取系统的核数
System.out.println(a.availableProcessors());
System.out.println("MAX_MEMORY = "+a.maxMemory()/1024);//虚拟机的最大可调节内存 -Xmx 最大值 在生产环境中最大值和初始值最好是一样大,忽高忽低
System.out.println("TOTAL_MEMORY = "+a.totalMemory()/1024);//虚拟机的内存总量 -Xms 初始值
}
结果:
MAX_MEMORY = 10240
TOTAL_MEMORY = 10240
[0.096s][info ][gc,heap,exit ] Heap
[0.096s][info ][gc,heap,exit ] garbage-first heap total 10240K, used 1024K [0x00000000ff600000, 0x0000000100000000)
[0.096s][info ][gc,heap,exit ] region size 1024K, 2 young (2048K), 0 survivors (0K)
[0.096s][info ][gc,heap,exit ] Metaspace used 623K, capacity 4535K, committed 4864K, reserved 1056768K
[0.096s][info ][gc,heap,exit ] class space used 54K, capacity 402K, committed 512K, reserved 1048576K
在jdk的bin目录下有jvm的图像监测工具: jvisualvm
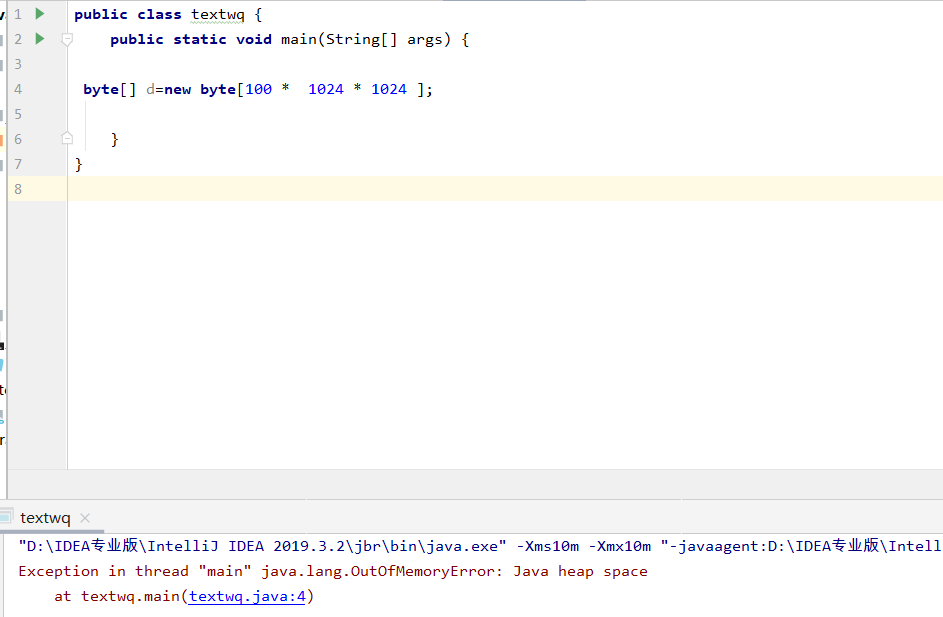
OOM(堆溢出):对象的中大小超过堆内存的大小
OOM的演示:将堆的初始大小和最大值调成10m,new一个100mb的对象
![]()
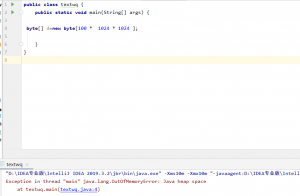
四,GC
GC垃圾回收器,本遍从两个角度解释gc的机制
1,GC怎么判断一个对象是否为垃圾?
1.1,引用计数法
在1.1版的jvm中用的GC用的是引用计数机制,
含义:当一个对象被其他对象引用则在计数器中加1,如果没有则减1,当为0时则被判断为垃圾,被GC回收
弊端:当对象与其他对象之间存在循环引用时,引用计数则判定不出来
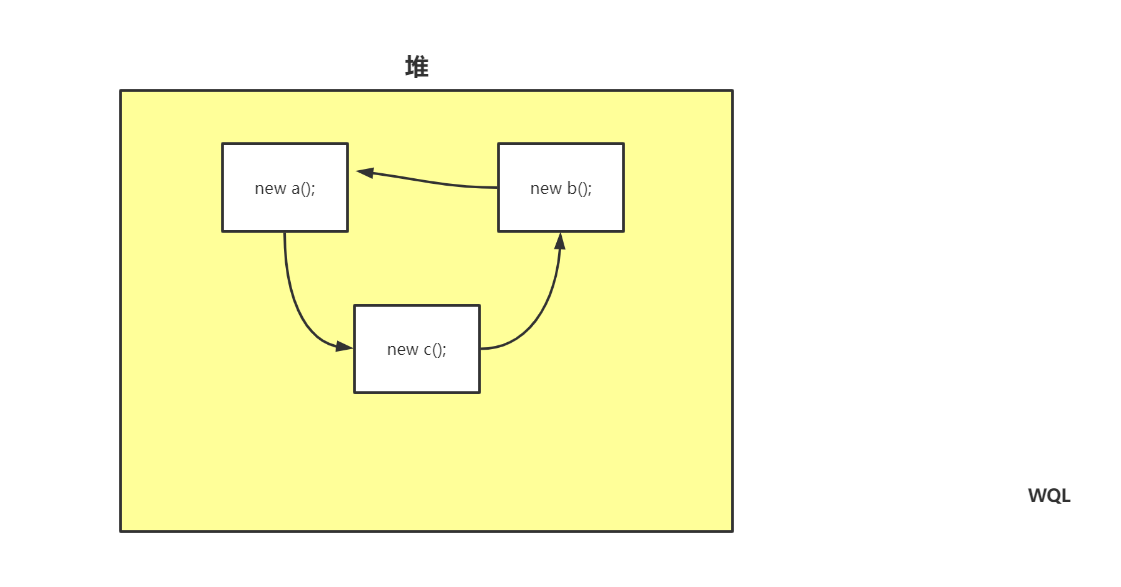
1.2,可达性分析法
现在依然在用的一种方法,弥补了引用计数的弊端,
2,GC是怎么回收垃圾的?
2.1,标记清除算法
通过可达性分析法判定一个类为垃圾时,将他标记,之后一次性删除
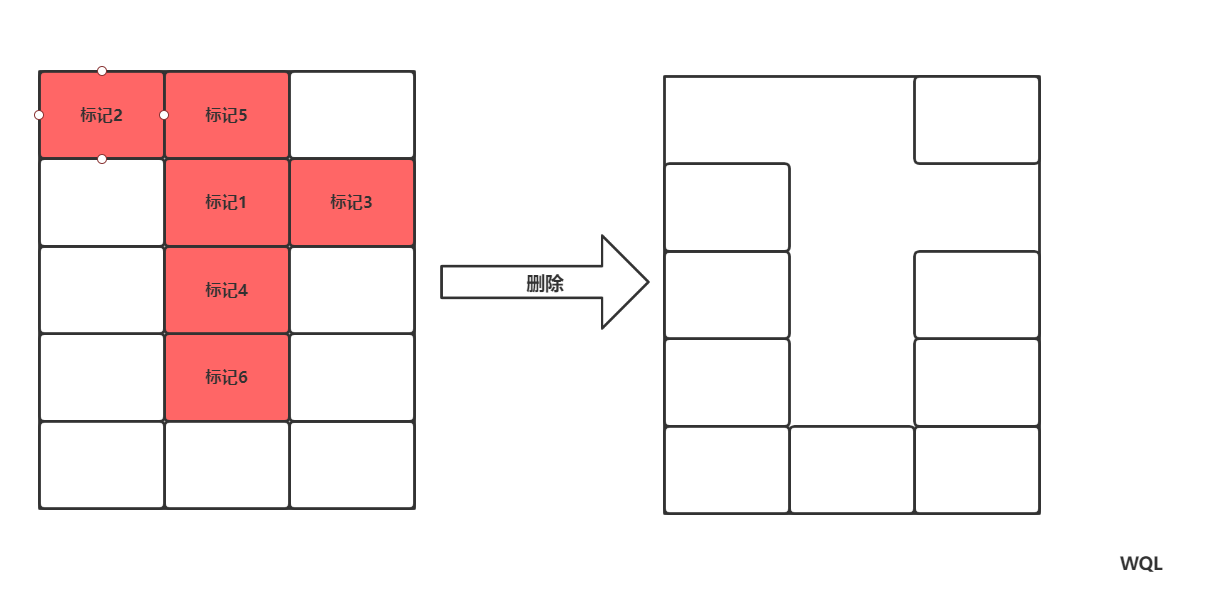
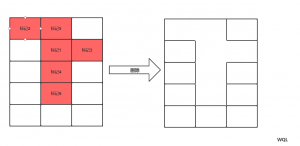
弊端:由图可知上面删除之后,删除之后产生大量内存碎片
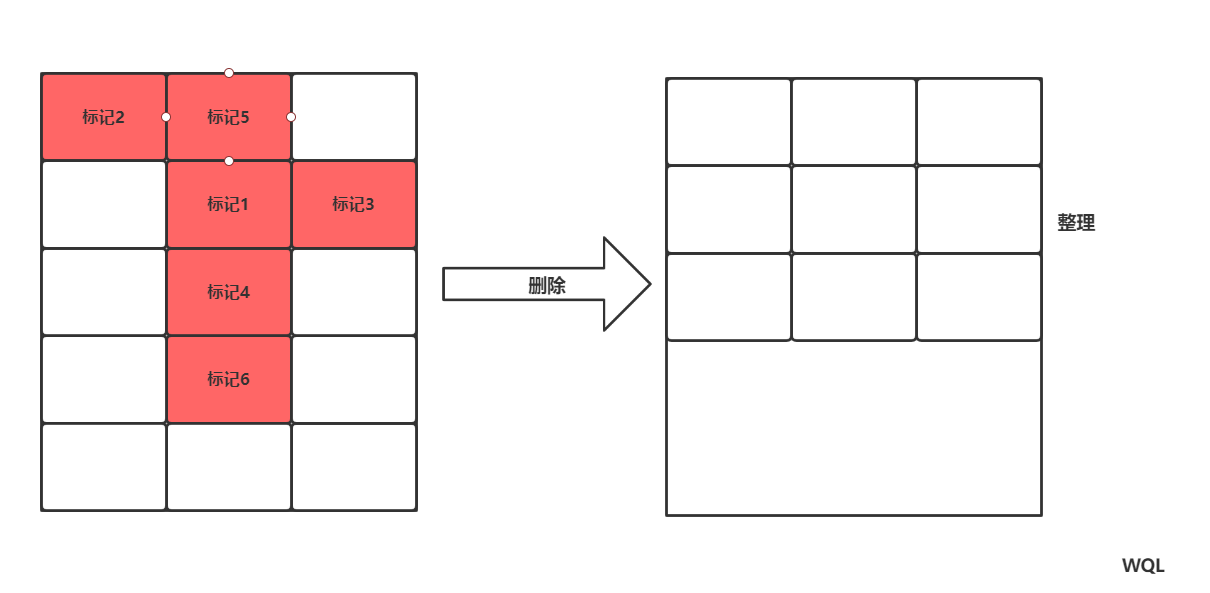
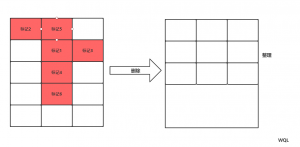
2.2,标记整理算法(标记压缩算法)
和标记清除类似,只是之后多了一个整理操作,减少内存的碎片化
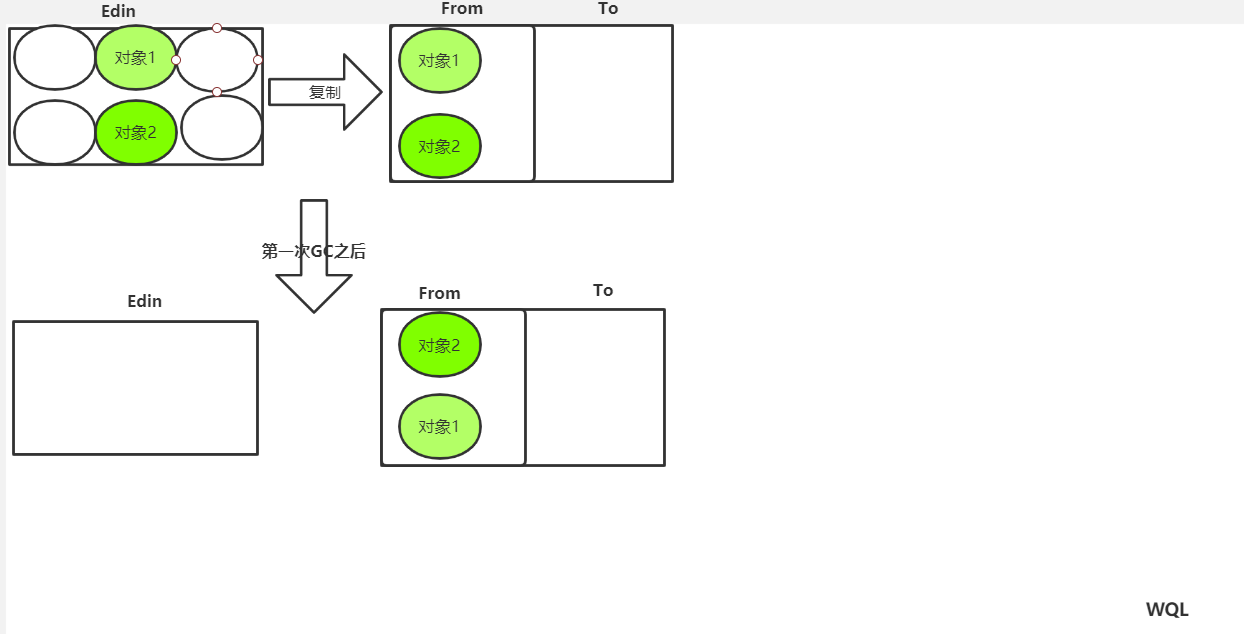
2.3,复制算法
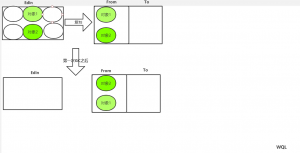
将不被删除的对象复制出来,放到专门的一块区域,再将之前的区域一次清空,复制算法指对的新生带,第一次GC时把Edin的存活对象,复制进From区,清空Edin,当第二次GC时,将Edin和From区的存活对象复制进To区,再清空Edin和From,以此类推。。
2.4,分代收集算法
其实是对标记清除,标记整理,复制算法的分代实现
复制算法本身复制就需要浪费内存,在老年代,大对象而且存活数大于死亡数,复制算法对空间占用大,而在新生代对象的存活率低,刚好顺从了复制算法的弊端
标记整理算法在老年代这中存活率高,对象大直接清除整理更好,而相比较在新生代,死亡数大,标记数大(标记也占空间)反而不适合
分代收集算法:就是在新生代用复制算法,在老年代用标记整理算法,分代治之
五,java栈和程序计算器
1,程序计数器
防止程序代码运行顺序出错,在方法调用时其他方法时,Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现,也就是说,在同一时刻一个处理器内核只会执行一条线程,处理器切换线程时并不会记录上一个线程执行到哪个位置,所以为了线程切换后依然能恢复到原位,每条线程都需要有各自独立的程序计数器。
2,java栈
java栈主要存放对象引用,作为线程独占区的栈每一个对象都有自己栈空间,与数据结构里的栈一样它是一个先进后出的容器,当一个对象调用了其他对象方法,就会形成压栈的操作
java栈主要存放Java方法的参数、局部变量、中间运算结果、返回值等数据
栈帧:java栈的实际存储形式,java栈实际以栈帧为存储格式,是用于支持虚拟机进行方法调用和方法执行的数据结构
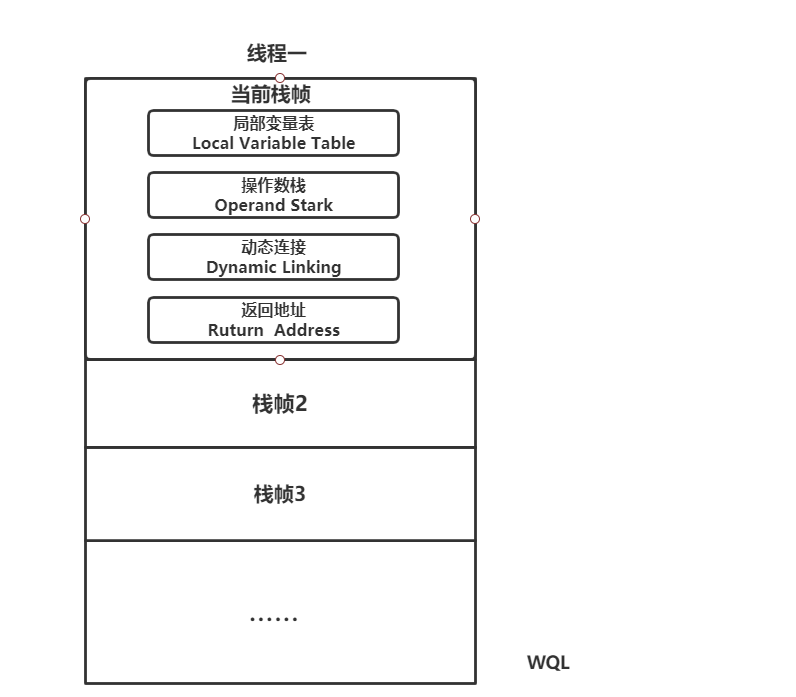
局部变量表:(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。并且在Java编译为Class文件时,就已经确定了该方法所需要分配的局部变量表的最大容量。
动态连接: 每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支付方法调用过程中的动态连接(Dynamic Linking),在类加载阶段中的解析阶段会将符号引用转为直接引用,这种转化也称为静态解析。另外的一部分将在每一次运行时期转化为直接引用。这部分称为动态连
操作数栈: 和局部变量表一样,在编译时期就已经确定了该方法所需要分配的局部变量表的最大容量。操作数栈的每一个元素可用是任意的Java数据类型,包括long和double。32位数据类型所占的栈容量为1,64位数据类型占用的栈容量为2, 当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的,在方法执行的过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是出栈 / 入栈操作。
栈和堆存储对象区别:
堆存储:
1,对象实体,
2,数组
3,全局变量
对象实体,数组,全局变量存储在堆中,除了这些,堆也会在栈中产生一个特殊变量(地址),这些特殊变量,指向堆中的对象实体和数组,他的指向被称做指针,堆中的存 储的内容,通过GC回收
栈存储:
1,基本数据类型
2,对象引用
栈中数据,在作用域外会被自动销毁
Comments | NOTHING