




每一种知识点在所处的不同阶段都有不一样的感受,现在将javaSE的重要知识点做一下深度复盘,我主要从集合,IO,String等做一个复盘,
一,IO流
IO流是java操作文件系统的统一称呼,它主要包括三个方面:File类,字节流,字符流
File类是文件操作如:删除,创建,重命名等
字节流和字符流是对文件内容的操作只是它们的操作单位不一样
一,File类
File类是Java对文件的操作类,在java.io.File包下
File类是文件和文件夹的抽象表现形式,java把文件和目录封装进File中,提供File的API,通过对File类的操作实现对文件的操作
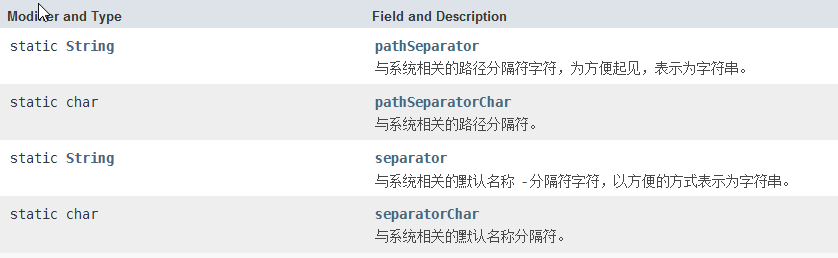
一,File类的四个静态变量
file类有四个属性变量,她们都是定义路径分隔符
pathSeparator:路径列表不同路径分隔符,在Linux中是 : windows是 ; 字符串型
pathSeparatorChar:路径列表不同路径分隔符,在Linux中是 : windows是 ; 字符型
separator:路径中间分隔符 在Linux是 / windows是 \\ 字符串型
separatorChar:路径中间分隔符 在Linux是 / windows是 \\ 字符型
源码:
private static final FileSystem fs = DefaultFileSystem.getFileSystem();//DefaultFileSystem只有一个方法返回WinNTFileSystem对象,它可以读取文件系统信息 public static final char separatorChar = fs.getSeparator(); public static final String separator = "" + separatorChar; public static final char pathSeparatorChar = fs.getPathSeparator(); //通过fs读取分隔符 public static final String pathSeparator = "" + pathSeparatorChar; //加空字符串直接转化为字符串类型
例:
System.out.print(File.pathSeparator+"\n"+File.pathSeparatorChar+"\n"+File.separator+"\n"+File.separatorChar); //输出:; ; \ \
二,File方法
1,file的基本方法
File有很多,我们挑几个重要的说
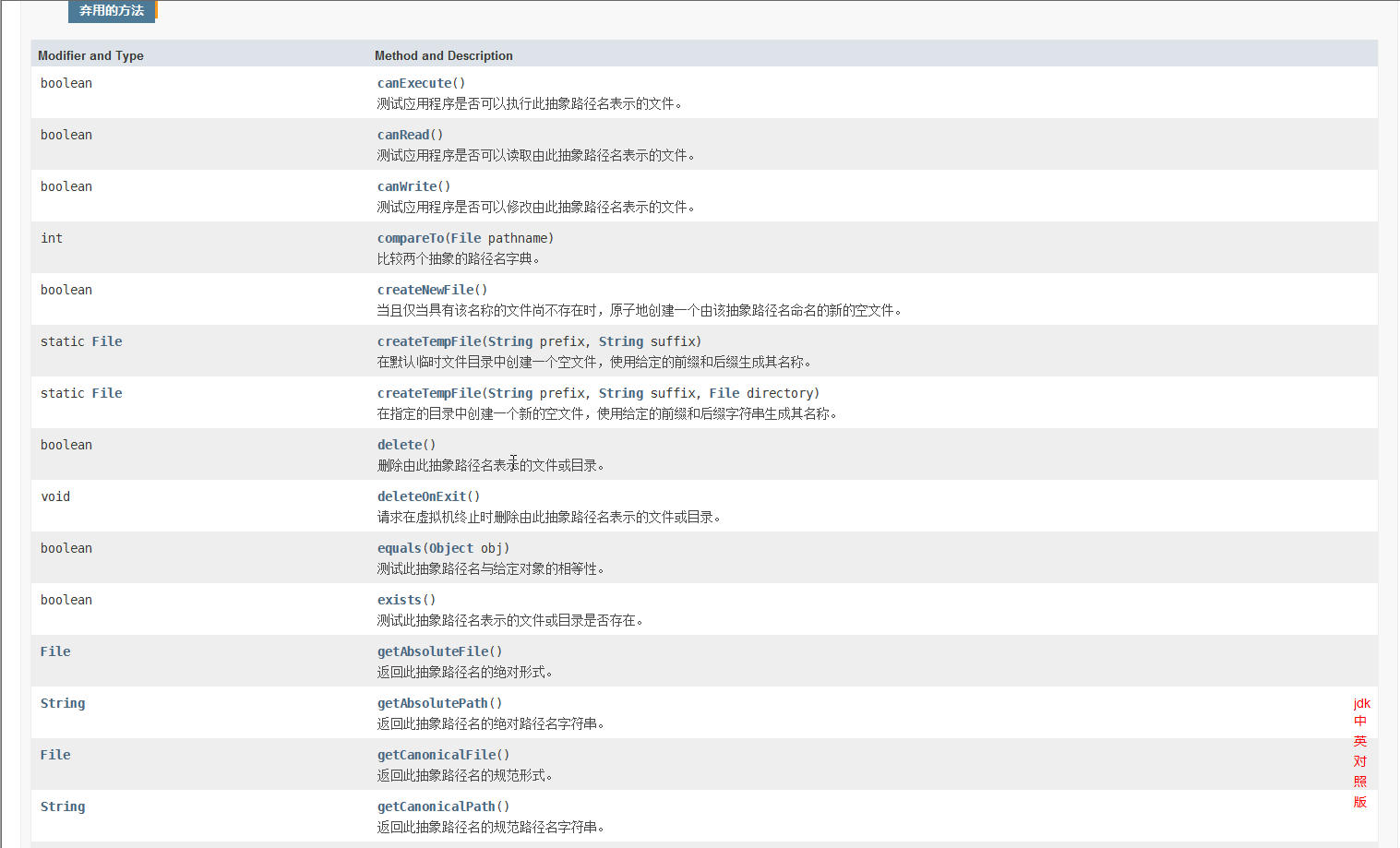

1,exist():判断文件是否存在(存在为真,不存在为假)
2,isFile:判断是否为文件
isDirectory:判断是否为目录
3,getAbsolutePath:获取文件的绝对路径
4,delect:删除文件,但文件必须为空
5,getname:获取文件名
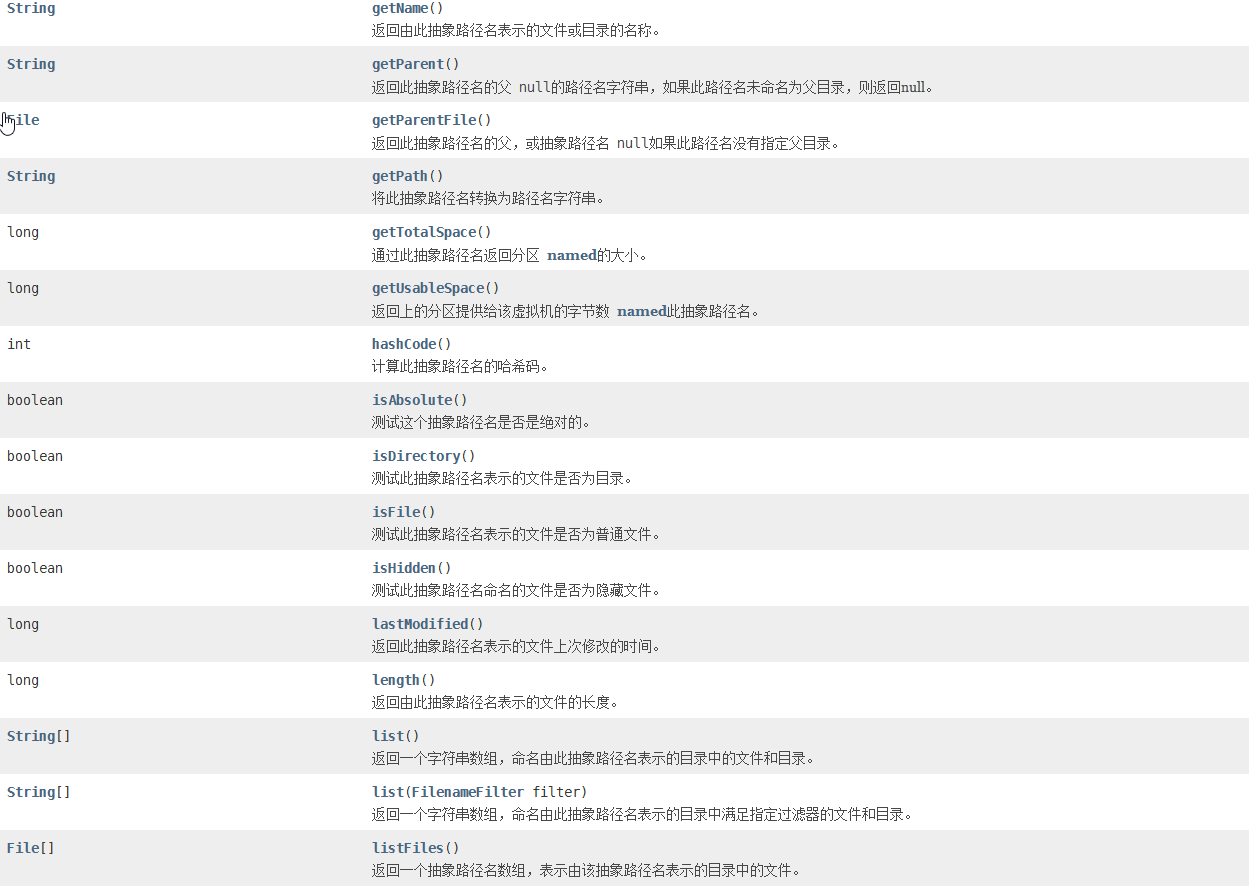
2,File的查看和过滤
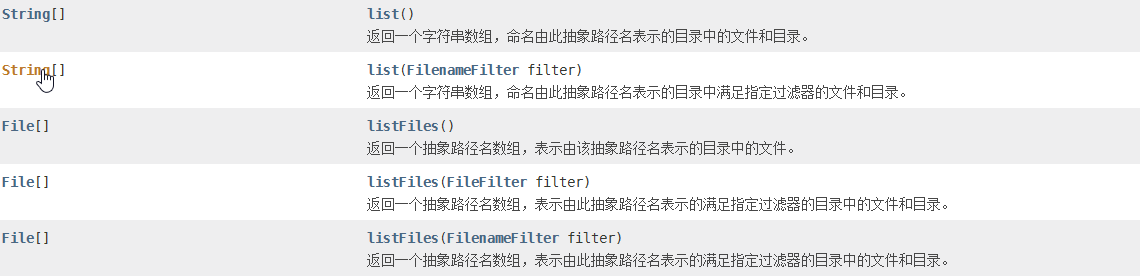
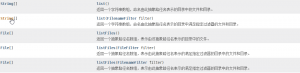
1,list方法
这个方法返回一个String数组,数组存储file文件名
list() :返回当前目录的所有文件名
list(FilenameFilter filter):通过过滤流返回文件名 后面说
例:
public static void listfile(File file) {
File[] path=file.listFiles();
for(File a:path) {
//输出文件内所有文件名
System.out.print(a.getName());
}}
2,listFiles方法
这个方法返回一个File数组,数组存储file对象
listfiles():返回当前目录的所有文件对象
list(FilenameFilter filter):通过过滤流返回文件对象
例:file递归删除文件
public static Boolean del(File file) {
Boolean f=false;
if(file.exists()) {
if(file.isDirectory()) {
File[] fe=file.listFiles();
for(File g:fe) {
f=del(g);
}
}else {
file.delete();
}
}else {
f=false;
}
return f;
}}
3,过滤流
IO中过滤流只是一个接口,他只有一个accept方法
过滤流分两种:
1,FilenameFilter :他的指定了文件名
源码:
public interface FilenameFilter {
/**
* Tests if a specified file should be included in a file list.
*
* @param dir the directory in which the file was found.
* @param name the name of the file.
* @return <code>true</code> if and only if the name should be
* included in the file list; <code>false</code> otherwise.
*/
//dir:文件对象 name:文件名
boolean accept(File dir, String name);
}
2,FileFilter:没有指定文件名的
源码:
public interface FileFilter {
/**
* Tests whether or not the specified abstract pathname should be
* included in a pathname list.
*
* @param pathname The abstract pathname to be tested
* @return <code>true</code> if and only if <code>pathname</code>
* should be included
*/
//file:文件对象
boolean accept(File pathname);
}
list和listfile使用文件流原理:
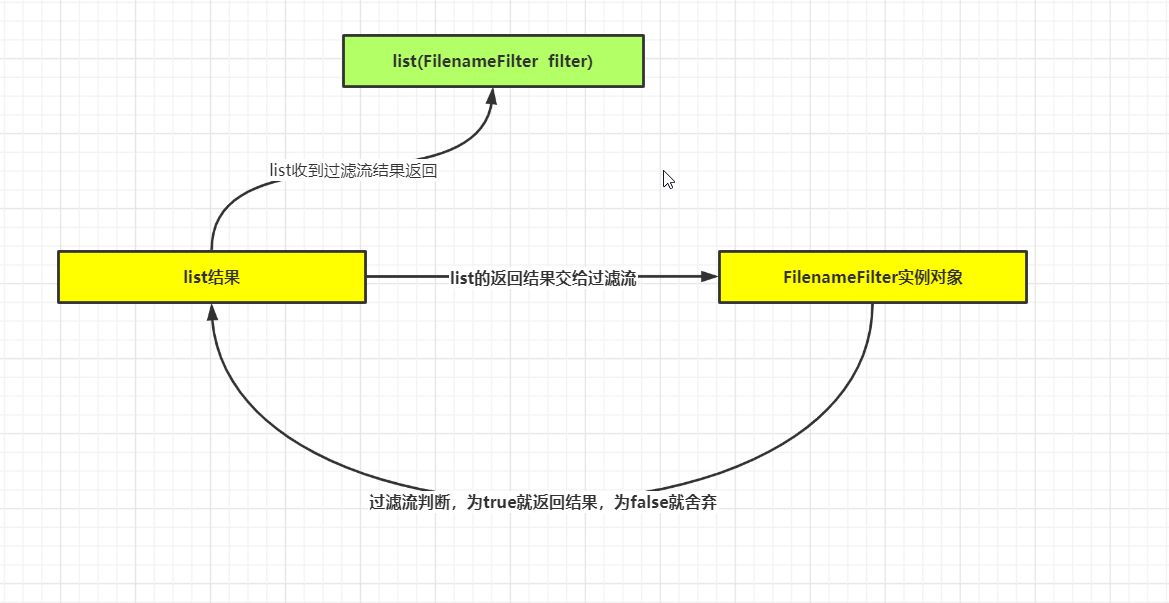
accept方法:当为true时返回
例: FilenameFilter实例:
public class filenamewql implements FilenameFilter{
@Override
public boolean accept(File dir, String name) {
Boolean bo=false;
//过滤出以txt结尾的文件
if(name.toLowerCase().endsWith(".txt")) {
bo=true;
}
//当返回为false,文件会被过滤掉,为true文件会进入数组
return bo;
}
}
FileFilter实例:
public class filterwql implements FileFilter {
@Override
public boolean accept(File pathname) {
// TODO Auto-generated method stub
Boolean bo=false;
//过滤出以txt结尾的文件
if(pathname.getName().toLowerCase().endsWith(".txt")) {
bo=true;
}
//当返回为false,文件会被过滤掉,为true文件会进入数组
return bo;
}
}
main方法:
public static void main(String[] args) {
filenamewql fq=new filenamewql();
filterwql wql=new filterwql();
File file=new File("C:\\Users\\wql\\Desktop\\wql");
File[] filefq=file.listFiles(fq);
for(File s:filefq) {
System.out.print(s.getName()+"\n");
}
//System.out.print(file.exists());
}
二,字节流和字符流
流的分类有很几种标准分类:流向,
IO流的底层运行原理:
javaIO -> JVM -> OS(操作系统) -> 文件完成写入或者读取
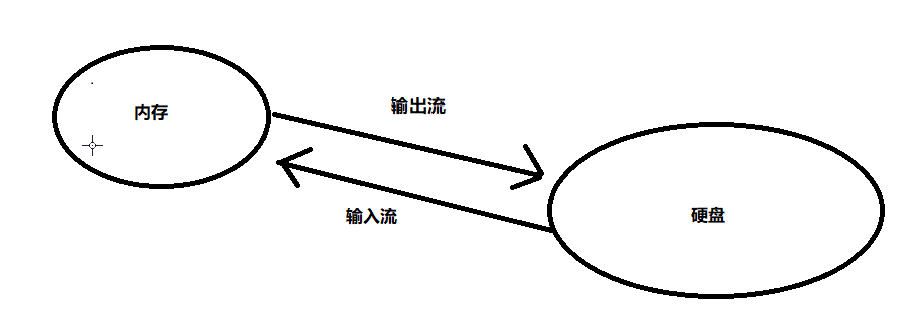
一,流向分类:
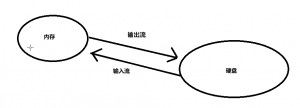
流按在内存和硬盘之间的走向来分
输入流(inputStream/readerStream):从硬盘到内存
输出流(output/writer):从内存到硬盘
二,按单位分类
流可以按两种单位传输数据:字符和字节
一个字符=两个字节=16bit
一个字节=8bit
字符:传输文本文件,传输二进制数据会破坏格式
字节:传输二进制数据,如:图片,音频,它也可以传输文本文件(但效率慢)
字符和字节分别针对不同的数据传输场景
字符流(reader/writer):按字符传输文件
字节流(inputStream/outputStream):按字节传输文件
三,按传输类型分类
这里的传输类型指的是:是否是源到源的传输(直接从内存到硬盘,是否经过中间处理)
节点流(低级流):直接源到源的传输,不经过中间处理
节点流也可以分类:
文件流:针对文件的传输,FileinputStream/FileoutputStream,Filereader/Filewriter
对象流(序列化流):ObjectinputStream/ObjectoutputStream
处理流(高级流:在低级流的基础上进行包装):不是源到源的传输,进行中间处理
处理流也有分类:
转化流:把字节流转换成字符流,InputStream/OutputStream
过滤流:对流进行中间处理,filterinputStream/filteroutputStream ,filterreader/filterwriter (过滤是接口,它有很多实现类)
过滤流的分类:
打印流:priintStream/printWriter
数据流(将其他数据转换为正确的基本数据类型值或字符串):DatainputStream/DataoutputStream


缓冲流:建立缓冲区,BufferedinputStream/BufferedoutputStream ,BufferedReader/BufferedWriter
二,IO流的结构
一,字节流结构
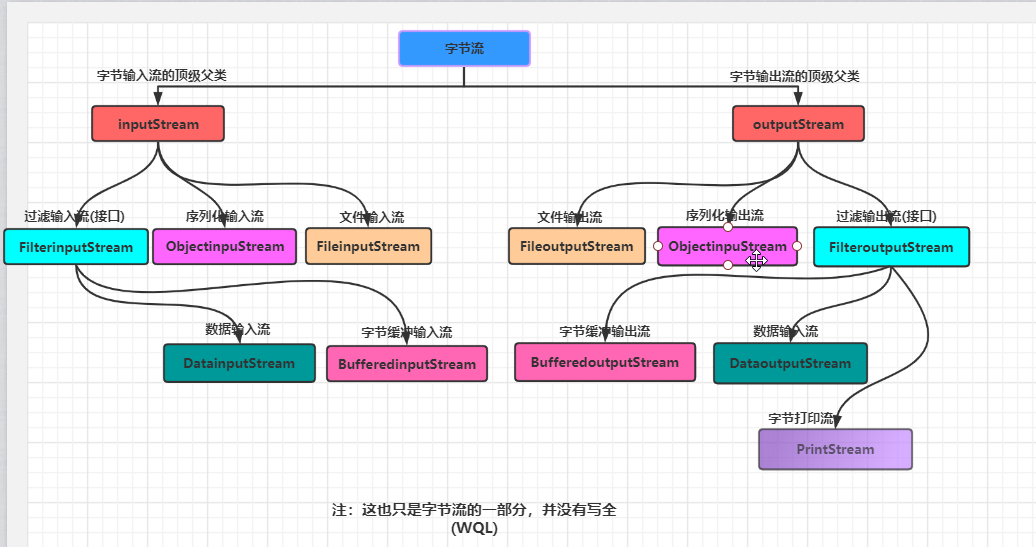
这张图只是我在字节流中选取出来的流,并不是完整的字节流结构(我认为常见的)
字节输入流和输出流的对比:字节输入流和输出流类结构大同小异,输出流多了个打印流
二,字符流结构
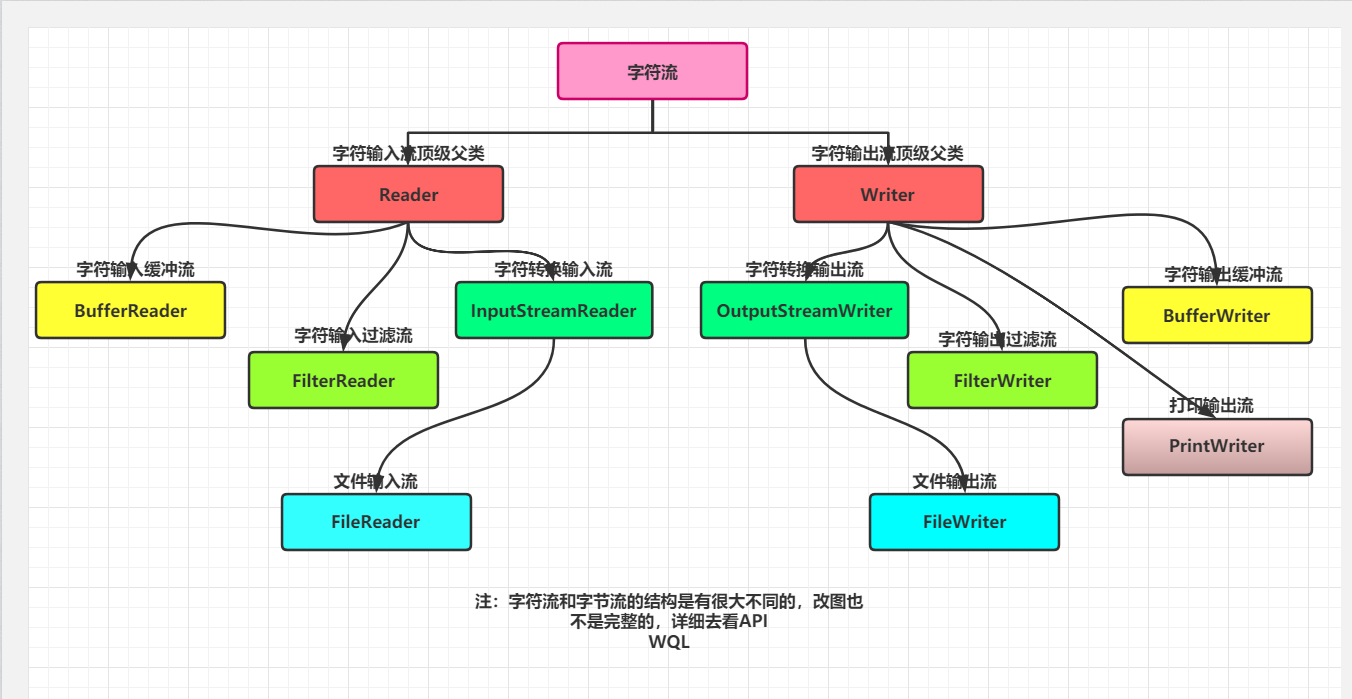
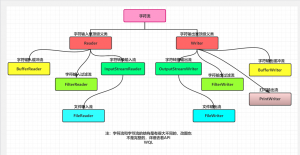
三,字节流和字符流结构对比
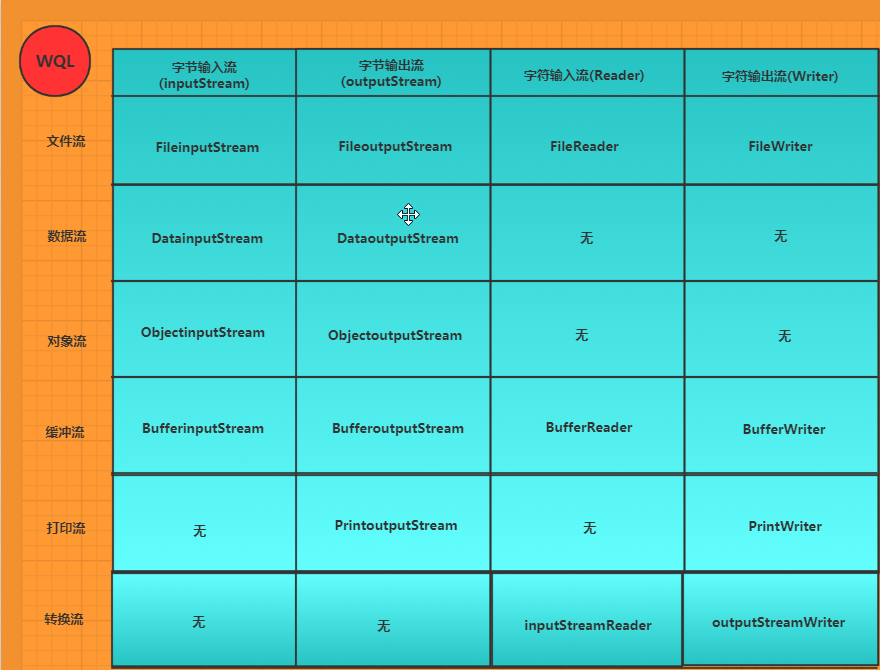
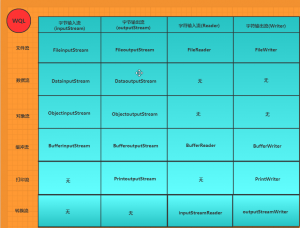
图中说明了字节流和字符流的异同
但字节流和字符类还有一个比较大的区别就是过滤流
在字节流中Filter接口包括了,缓冲流(Buffer),数据流(Data),打印流(Print),但字符类流中只有一个PushbackReader(字符读取器)
字节过滤流类结构图:


字符过滤流类结构图:

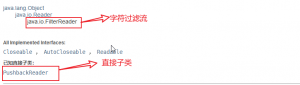
三,流的操作
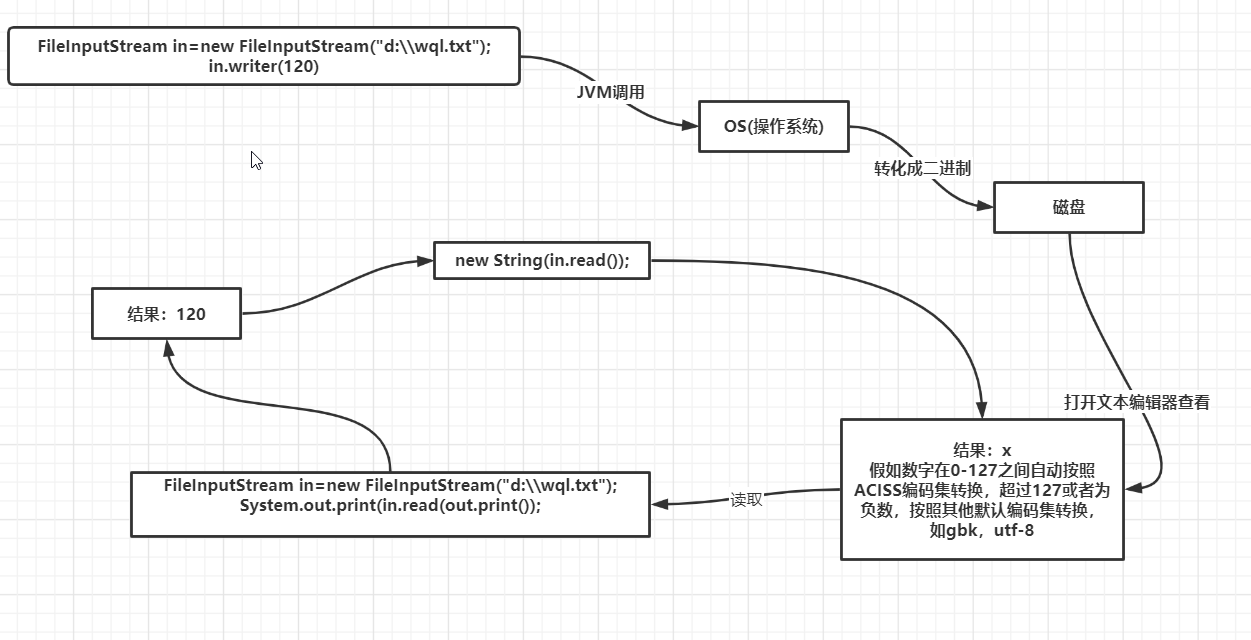
一,字节流和文本编辑打开底层原理
一,字节流底层原理
单字节:数字,字母
但一个字节其实都是一个十进制数,当写入(writer)的是字母,通过ACISS码,转化成十进制数,然后jvm调用os写入磁盘,操作系统把这个十进制数转化成二近制数写入磁盘
在读入(read),操作系统把二进制数转换成十进制数,jvm读入,假如调用String方法,可以把十进制数在通过ACISS码在重新转化成字母或者数字
结论:
1,字节输入输出流依赖字节编码集(ASICC)
2,在read和writer中写入十进制数不表示十进制本身
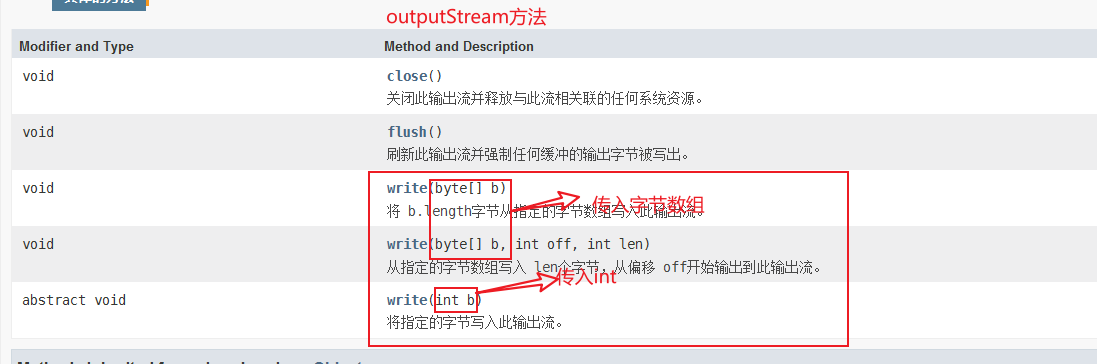
outputStream方法:
inputStream方法:
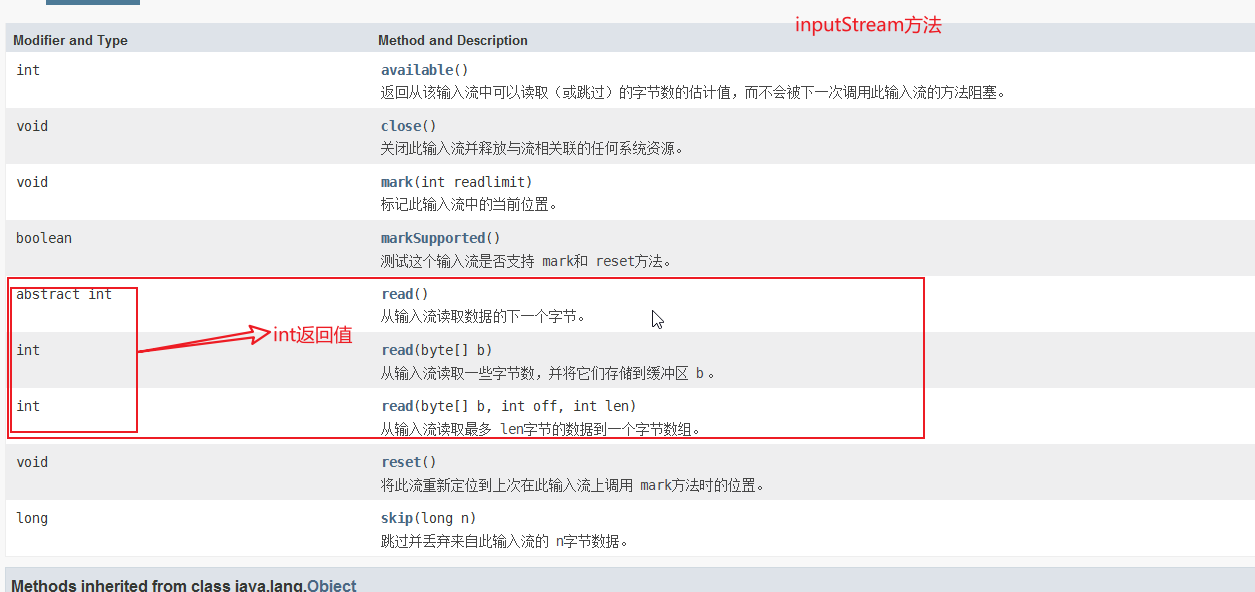
注:字节数组,存储的是经过编码集,编码后的经过,它的最大值小于128(Aciss编码)
FileInputStream in=new FileInputStream("d:\\a.txt"); //文件内容:wql wql的ACISS分别是 119 ,113,108
byte[] by=new byte[1024];
int len;
while((len=in.read(by))!=-1) {
System.out.println(new String(by,0,len));
System.out.print(by[0]+"\t"+by[1]+"\t"+by[2]);
}
结果:
wql 119 113 108
字节流的编码:
FileOutputStream out=new FileOutputStream("d:\\a.txt");
FileInputStream in=new FileInputStream("d:\\a.txt");
//把字节数组写入文件
out.write(new byte[]{119,113,108});
out.close();
//读取文件
int len;
while((len=in.read())!=-1) {
System.out.print(len+"="+(char)len+"\n");
}
in.close();
结果: 119=w 113=q 108=l
当写入的是数字超过或者为负数,会被当成字符处理,注:如果数字是负数或超过127,它的后一个正数也会被当成字符串处理(因为,一个字符两个字节,需要在填充一个字节)
例:
FileOutputStream out=new FileOutputStream("d:\\a.txt");
FileInputStream in=new FileInputStream("d:\\a.txt");
//把字节数组写入文件
out.write(new byte[]{-127,-113,113,-108,126});//写入负数
out.close();
byte[] by=new byte[14];
//读取文件
int len;
while((len=in.read(by))!=-1) {
System.out.print(new String(by));
}
in.close();
结果:
亸q攡
注:在字符编码集中,gbk中一个字符占2两个字节,utf-8中占3个字节
字节流读取和写入字符:
FileOutputStream out=new FileOutputStream("d:\\a.txt");
FileInputStream in=new FileInputStream("d:\\a.txt");
//把字符转化成byte数组写入文件
out.write(new String("你好傅晴").getBytes());
out.close();
byte[] by=new byte[14];
//读取文件
int len;
while((len=in.read(by))!=-1) {
System.out.print(new String(by));
}
in.close();
结果:
你好傅晴
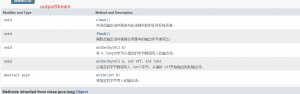
二,流的基本操作
流的操作无非就是read和writer,
一,输入流
字节流:
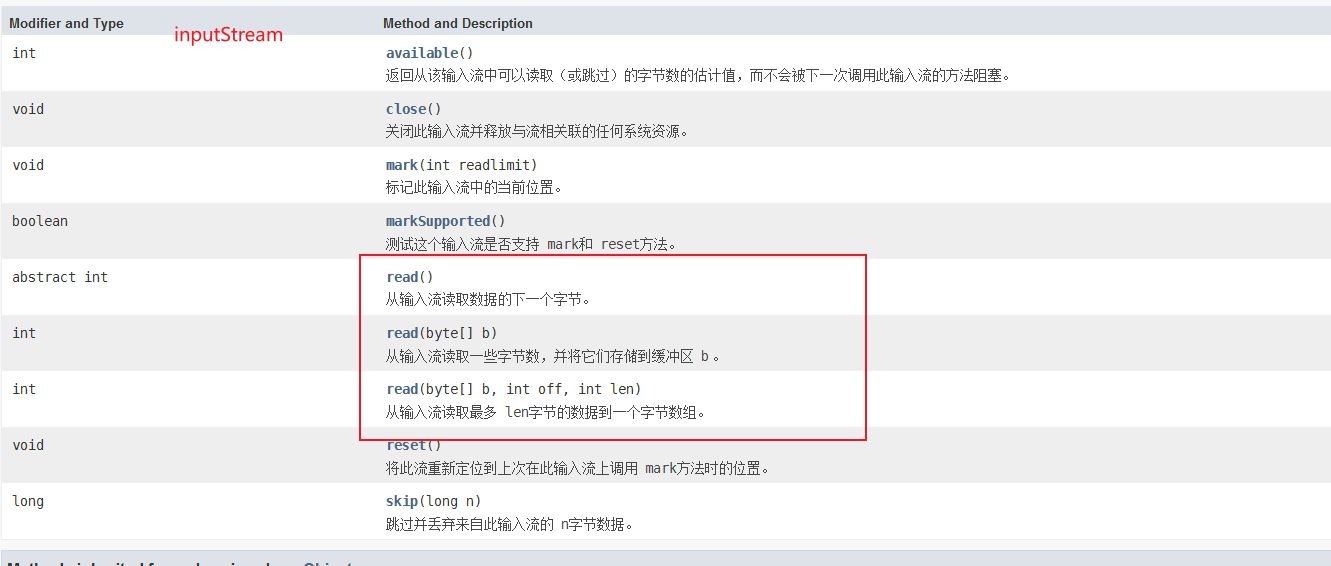
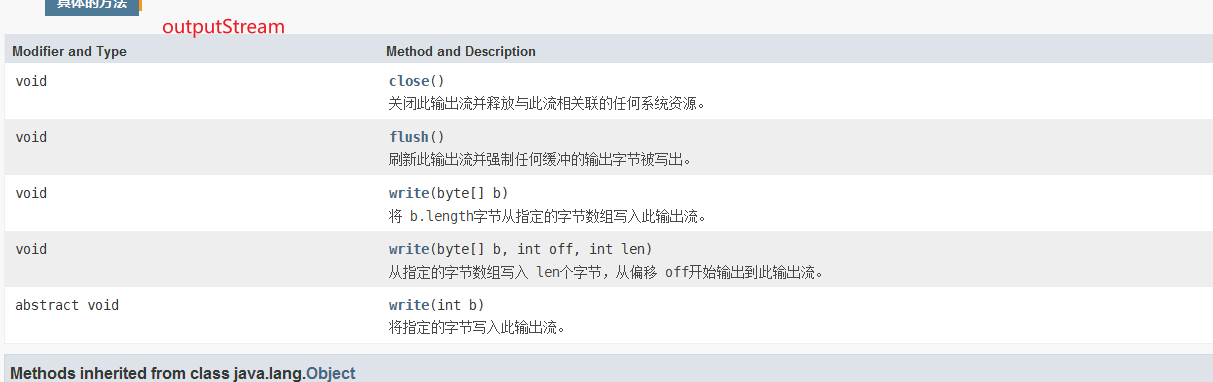
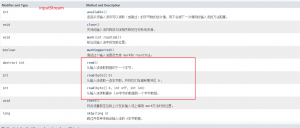
1,单字节读取
read方法内部维护着一个指针,当每调用一次read读取,指针会向后移动一位,并返回当前值,但为空时返回-1
例:
FileInputStream file = new FileInputStream(new File("D:\\a.txt")); //文件内容:你好傅晴
int len;
while((len=file.read())!=-1) {//read内有一个指针,每一次read都往后移一位,并返回当前指针的值,单字节读取效率慢
System.out.print(len+"\t");
}
结果:
196 227 186 195 184 181 199 231
错误写法:
FileInputStream file = new FileInputStream(new File("D:\\a.txt")); //文件内容:你好傅晴
while((file.read())!=-1) {//file它是同一个对象调用的是同一个方法,是同一个指针,一个方法交替读取,
System.out.print(file.read()+"\t");//读取的是相隔的4给字节
结果:
227 195 181 231
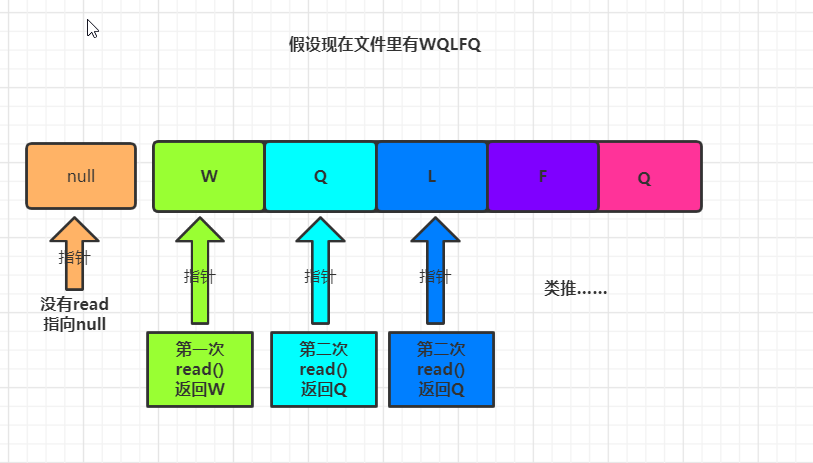
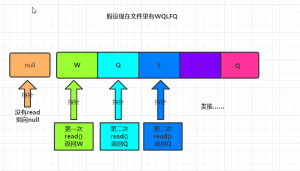
2,多字节读取
1,read(byte[] a)
多字节读取用到read(byte[] a) 和read(byte[] a,int off,int len)
这个方法将文件读入byte数组中,然后从byte数组中读取文件,而read(byte[] a)的返回值是数组对应值的下标

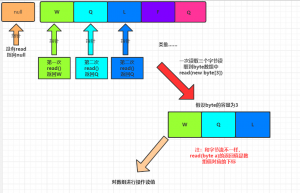
例:
FileInputStream file = new FileInputStream(new File("D:\\a.txt")); //内容:WQLFQ
int len;
byte[] by=new byte[3];
while((len=file.read(by))!=-1) {
System.out.println(len);
System.out.print(new String(by));
}
结果:
3 WQL2 FQL
因为5个字节,容量为3的数组,第一次len为三,说明数组是满的,输出WQL,第二次数组容量依旧3,但只存储了两个有效值,所以len为2,因为byte为3,还有一个空,就会拿前面的元素来填充所有,就有FQL
2,偏移量的设置
read(byte[] by , int off,int len)
off起始位置:都为0,数组起始位置为0
len:偏移量 ,就把read返回值填充进去
例:
FileInputStream file = new FileInputStream(new File("D:\\a.txt")); //内容:WQLFQ
int len;
int pian=1;
byte[] by=new byte[3];
while((len=file.read(by,0,pian))!=-1) {
//System.out.println(len);
System.out.print(new String(by));//String也可以设置偏移量String(byte,int off,int len)
pian=+1;
}
结果:
W Q L F Q
四,高级流的操作
一,缓冲流(buffer)
缓冲流是在输入流基础上的代理,在流在建立一个缓冲区
API:
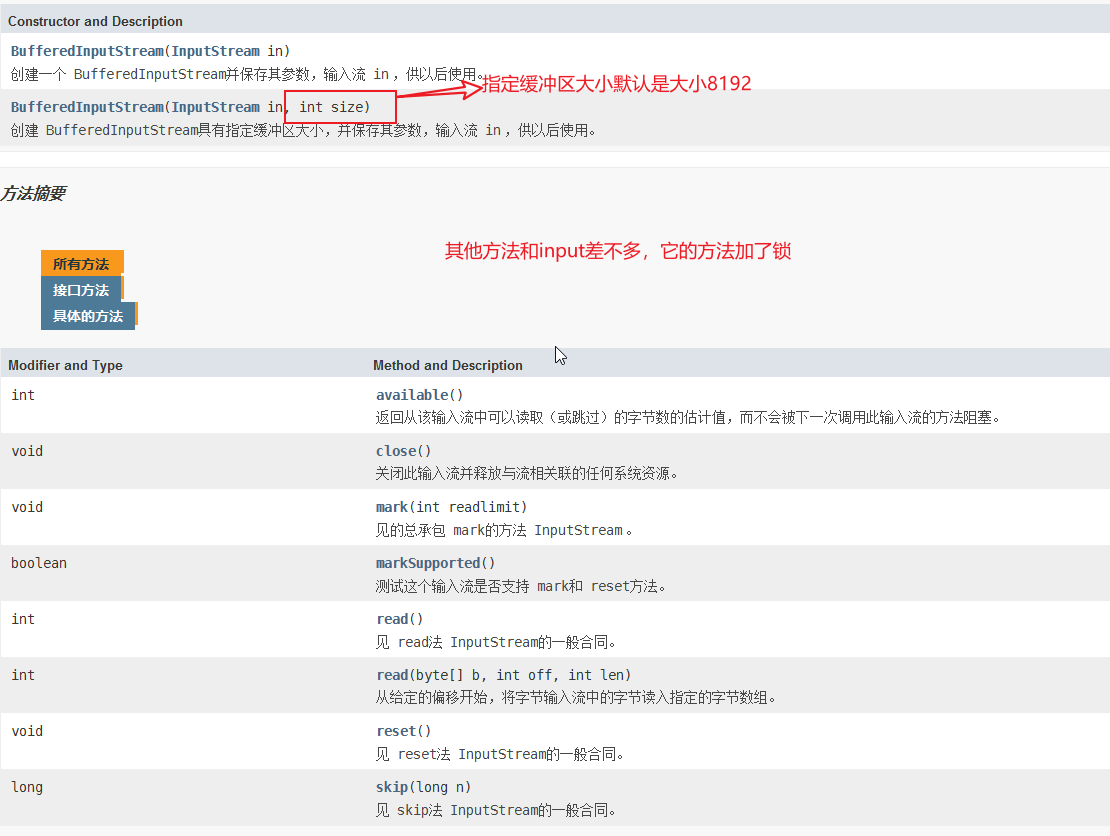
源码:
//成员变量:
//缓冲区默认初始化容量
private static int DEFAULT_BUFFER_SIZE = 8192;
//最大容量
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
//底层用到了了native方法调用了c
private static final Unsafe U = Unsafe.getUnsafe();
//缓冲区偏移量
private static final long BUF_OFFSET
= U.objectFieldOffset(BufferedInputStream.class, "buf");
//缓冲字节数组
protected volatile byte[] buf;
//字节数组的统计数量
protected int count;
//方法
//构造方法
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {//size数组容量小于0报异常
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];//初始化数组
}
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
//其他重要方法
//初始化数组方法
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
//核心方法,填充方法
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte[] nbuf = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!U.compareAndSetObject(this, BUF_OFFSET, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
//读取方法:
public synchronized int read() throws IOException {
if (pos >= count) {
fill();//调用fill
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
其他不说了
缓存流的使用:
InputStream in=new FileInputStream(new File("d:\\a.txt"));
FilterInputStream buff=new BufferedInputStream(in);//静态代理模式
byte[] by=new byte[2];
int len;
while((len=buff.read(by))!=-1) {
System.out.print(new String(by,0,len));
}
结果:
哈哈,傅晴
二,序列化流(object)
对象流是在inputStream和ouputStream独有的,对象流就把对先写入文件中,进行持久化保存,它要实现序列化接口
数据的状态:
持久态:硬盘上的数据
游离态:运行在内存中的数据
序列化:把游离态的数据,序列化到文件中或者网络传输
反序列化:把序列化的数据,反序列化到程序内存中运行
API:
构造:
![]()
序列化接口:Serializabl接口
Serializabl是一个标记接口,只是一种标识
标记接口:接口内没有任何方法
函数式接口:接口内只有一个方法
源码:
public interface Serializable {
}
它没有然后方法只是一个标记接口
实现该接口需要定义UID
private static final long serialVersionUID = 658047285L;
序列化必须定义UID序列号:因为在程序序列到文件中之后,万一你程序的实体类之后经过了更改,UID可以作为标识
操作:
建一个序列化class:
public class hh implements Serializable {
private static final long serialVersionUID = 658047285L;//定义一个序列号
public void w() {
System.out.print("傅大哥");
}}
对象流:
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
ObjectInputStream ob=new ObjectInputStream(new FileInputStream(new File ("D:\\b.txt")));
ObjectOutputStream out=new ObjectOutputStream(new FileOutputStream(new File("D:\\b.txt")));
writerwq(out);
hh hh = (hh)readwq(ob);
hh.w();
}
public static void writerwq(ObjectOutputStream out) throws IOException {
hh g=new hh();
out.writeObject(g);//把hh类序列化到文件中
out.close();
}
public static Object readwq(ObjectInputStream ob) throws ClassNotFoundException, IOException {
Object s=ob.readObject();//读取文件中的对象
ob.close();
return s;
}
结果:
傅大哥
三,打印流
打印流在字节流和字符流中只有输出的时候用到
1,System中打印流
打印流在我们操作中是最常见的比如:System.out.print其实也是一种打印流,我们先来看看System中的打印流


注意:System的打印流是直接跟控制台挂钩的,我们自己定义的打印流无法直接连接控制台
1,System.in(标准输入):从控制台输入
例1:
while(true) {
int a=System.in.read();//默认输入的字符,转化成编码值
System.out.print(a);
if(a==49) {
break;
}
}
结果:
23 50511310 43 525113 10 52531310 56 53541310 tert 1161011141161310 1 49
例2:
InputStream in = System.in;
int len;
byte[] by=new byte[2];
while((len=in.read(by))!=-1) {
System.out.print(new String(by,0,len));
}
结果:
傅晴 傅晴 I I LOVE YOU LOVE YOU
2,System.err标准错误
标准错误:将错误信息打印到控制台
//将错误信息打印到文件,在日志框架中都用到
System.setErr(new PrintStream(new File("d:\\c.txt")));//默认是打印打印到控制台,我们修改到文件
//定义一个报错
int a=0/0;
文件结果:


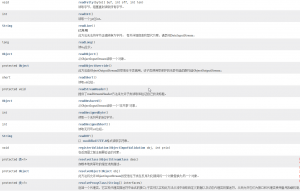
错误设置API:
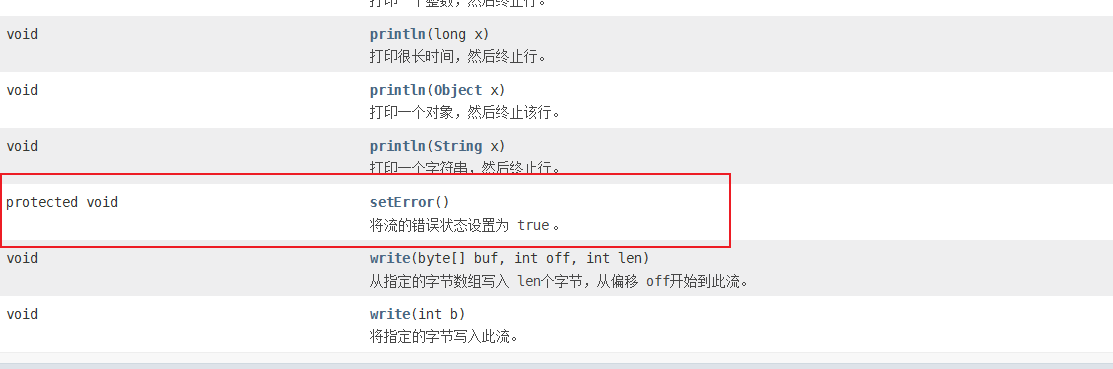
3,标准输出
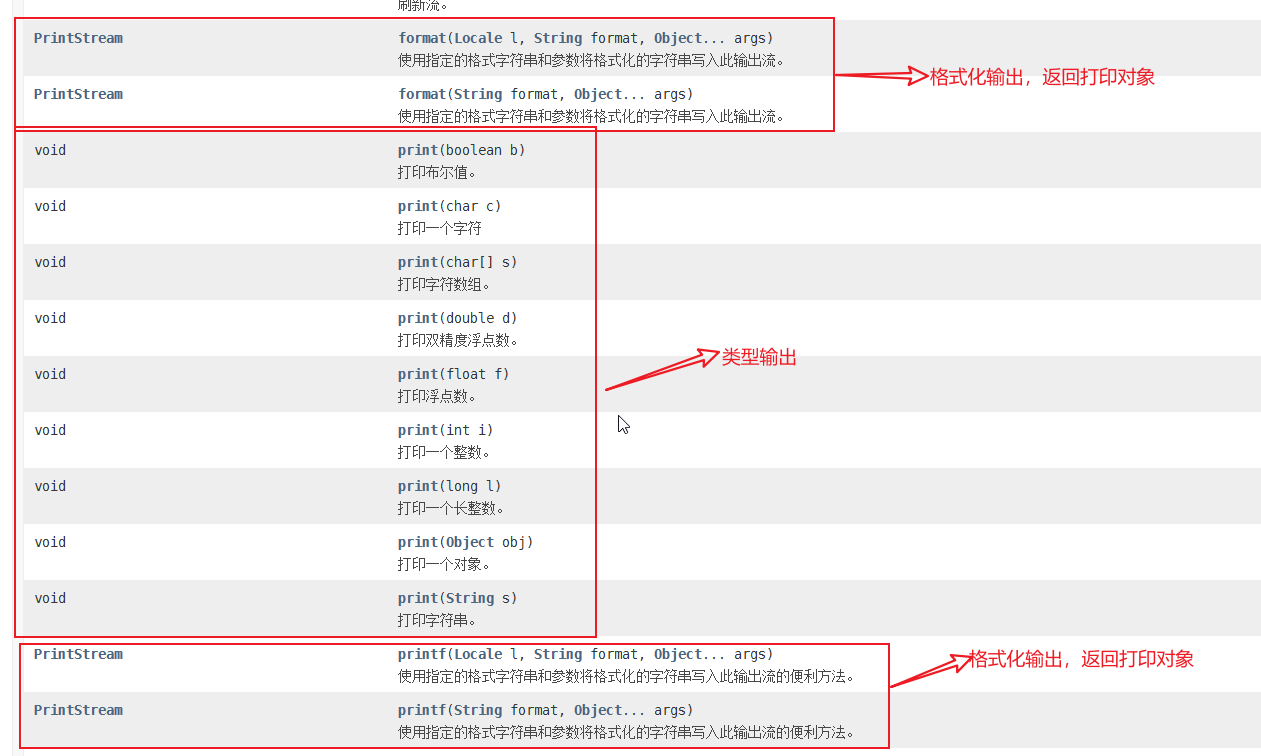
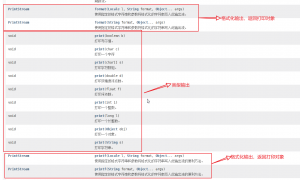
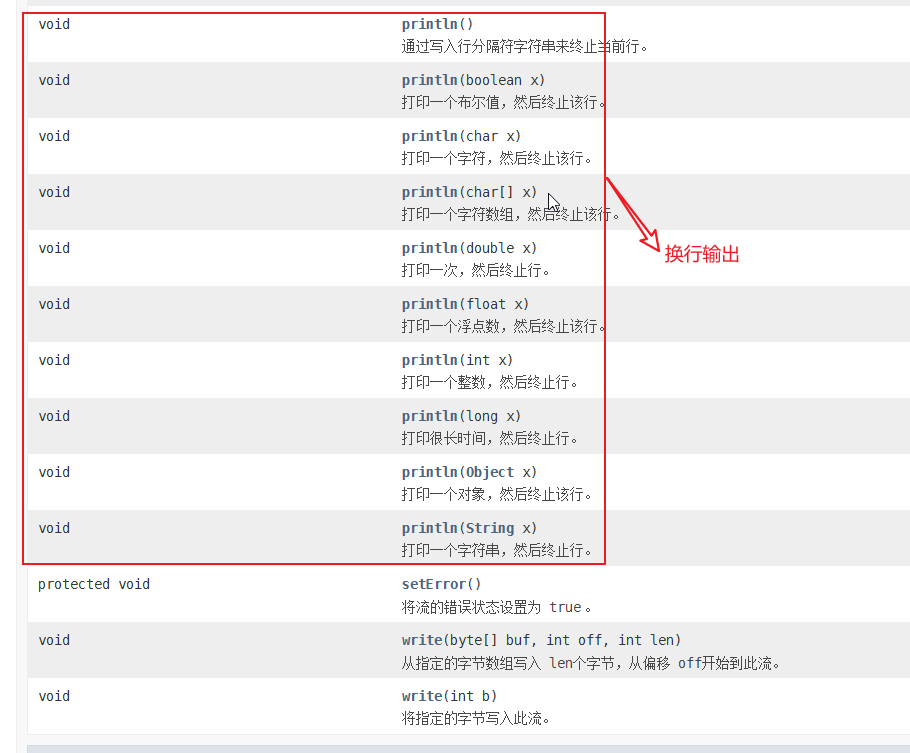
注意:在print和println有一个原样输出的功能,不会像其他输出一样将int转化成编码值
2,自定义打印流(不仔细谈)
PrintStream a=new PrintStream(new File("d:\\c.txt"));
a.append("傅晴,哈哈哈哈");//追加打印
a.print("牛逼了");//覆盖
四,转换流
转换流:将字节流转化成字符流,不可逆
输入转换流:
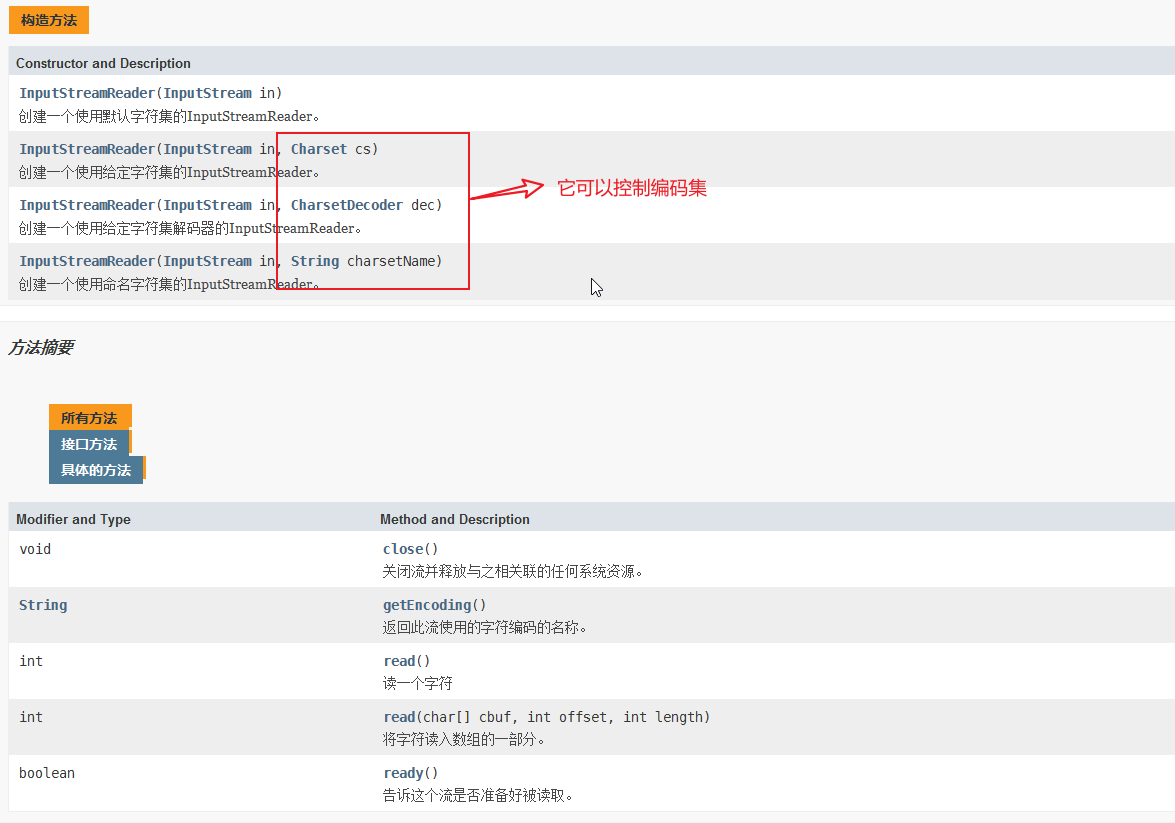
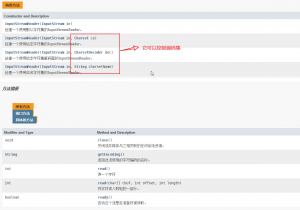
输出转换流:
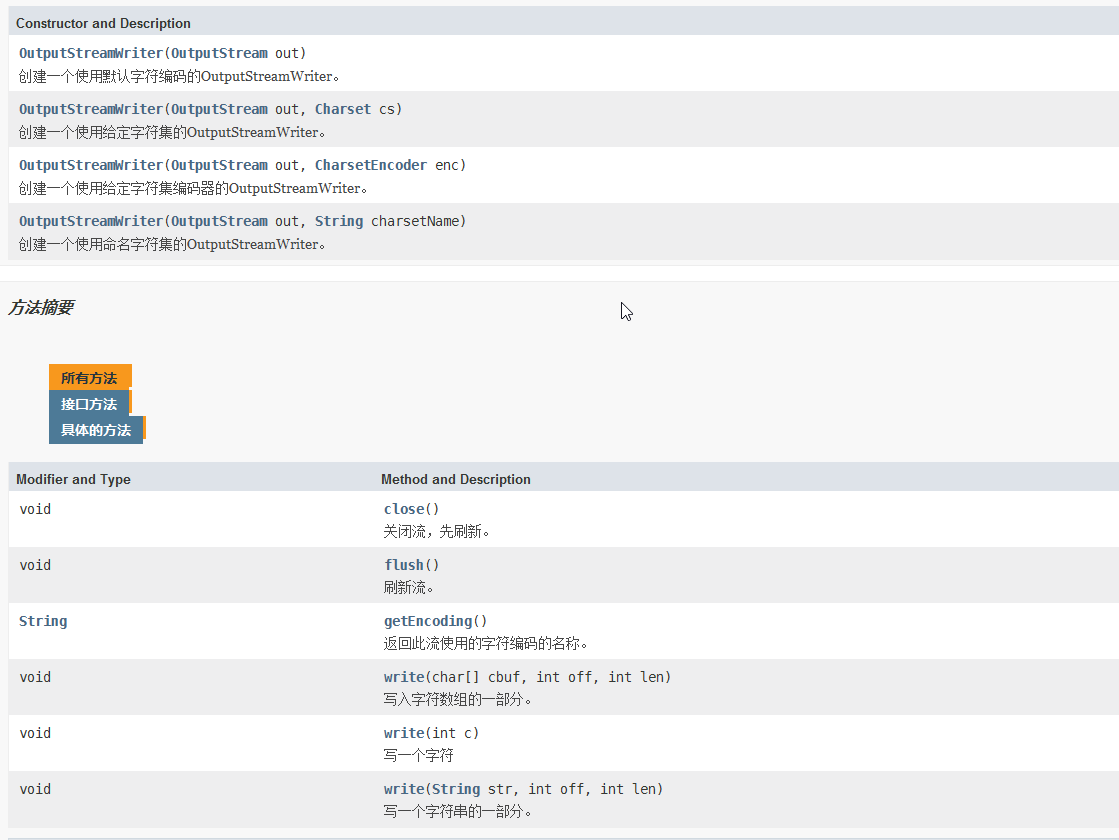
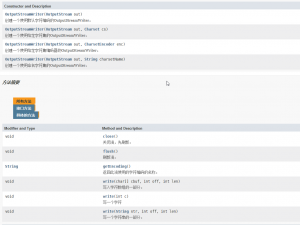
例:
//转换流:字节流 ->字符流
InputStream file=new FileInputStream(new File("d:\\b.txt"));//结果:FQ I LOVE YOU
InputStreamReader wql = new InputStreamReader(file);
char[] ch = new char[2];
int len;
while((len=wql.read(ch))!=-1) {
System.out.print(new String(ch,0,len));
}
结果:
FQ I LOVE YOU
Comments | NOTHING