




xml是基于拓展的数据传输语言,在配置文件会经常用到, 如Hadoop,zookeeper等,它的解析有四种:DOM,DOM4J,SAX,JDOM
一,XML
一,XML的作用和特定
XML(Extensible Markup Language):标记拓展性语言
特点:
1,XML是一组标签,没有固定语法
2,XML是一种独立于操作系统和编程语言的一种独立语言
3,它主要用于实现不同系统的数据传输和应用配置
4,XML是可拓展的,和HTML不同它没有被预定义,标签可以自由创造
5,XML是层级化的,可以看成是一个树结构
作用:
1,数据交互与传输
2,配置应用程序和框架,灵活配置降低耦合
3,是Ajax的基础
二,XML的格式
XML文件结构主要由两部分组成:
1,文档声明
2,文档描述信息
一,文档声明
文档声明是创建时系统自行声明的,在文件的第一行
声明内容:<?xml version="1.0" encoding="UTF-8"?>
xml:xml文件标识
version:版本号
encoding:字符编码集
二,文档的文件描述信息
描述信息是xml的内容部分
一,文档描述信息的格式
文档描述信息由一组组标签组成,它是标签的层级结构
标签格式:<标签名 属性格式>标签值</标签名>
属性格式:属性名=属性值
二,文档描述信息的层级结构
根标签:唯一的,包含了所有标签
父标签:对于直接子标签而言
子标签:对于父标签而言
邻居标签:同一层级的两个标签
例:
<phones> <wql>"节点的值"</wql> <phone name="oppo"> <type name="Rean1"></type> <type name="Rean2"></type> </phone> <phone name="Apple"> <type name="x11"></type> <type name="x10"></type> </phone> </phones>
phones:根标签
phone:根标签下的子标签,属性名是name,type标签的父标签,无属性值
type:phone的子标签,属性名为name,无属性值
三,XML的标签的编写格式和注意事项
XML的注释格式:<!--注释内容-->
一,XML的特定字符
1,XML文档属性值中不能直接包含 < 和 &符
2,不建议使用 " ,' ,>符
在xml解析过程中,<符会被作为标签开始符,两个<会冲突报错
单引号和双引号,表示字符串,属性值的多重嵌套任意报错
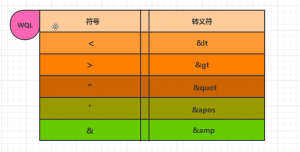
二,XML的转义符列表
XML的转义符列表,是针对几个特定预定义字符造成解析错误,要使用这些符合可以用转义符代替

三,CDATA
CDATA是xml的一个特殊的存在,CDATA中的数据会被XML解析器统一解析为文本数据
CDATA的作用:当需要写很多个特殊字符作为文本内容时,使用转义符过于麻烦,可以使用CDATA
格式:<![CDATA[数据内容]]>
四,XML书写的注意点
1,XML对大小写敏感
2,XML必须正确进行嵌套
3,同级标签以缩减对齐
4,元素名称可以包含字母,数字或者其他字符
5,元素名称不能以数字和标点符合开头
6,元素名称不能有空格
五,XML的命名空间
1,命名可空间的主要作用
命名空间主要是解决xml命名重名问题,当一个xml文件,有多个重名name时可以通过命名空间来解决命名冲突问题,命名空间是依赖于其他url的
2,命名空间解决命名冲突
例:一个有命名冲突的xml文件
<?xml version="1.0" encoding="UTF-8"?>
<wqls>
<wql></wql>
<wql>
<wql></wql>
</wql>
</wqls>
命名空间解决:
<?xml version="1.0" encoding="UTF-8"?>
<wqls xmlns:a="" xmlns:b="">
<a:wql></a:wql>
<b:wql>
<b:wql></b:wql>
</b:wql>
</wqls>
命名空间定义方式:
xmlns: 命名前缀 = "url地址"
二,XML的解析方式
XML解析有四种方式:DOM,SAX,DOM4J,JDOM
DOM和SAX属于底层接口
DOM4j和JDOM是对底层接口的封装
无论是底层接口还是封装接口,都有其特性
一,DOM
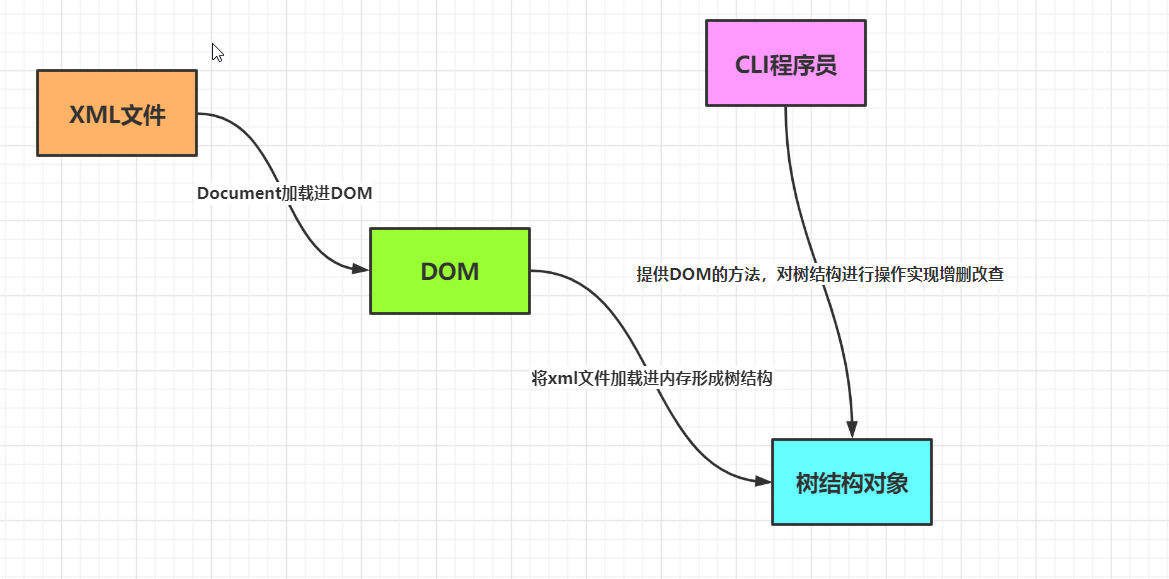
DOM是通用的接口,它和其他封装型接口不同,它独立于编程语言,它由W3C提供,用于解析XML文件,在JavaScript中也有使用
DOM的特点:
1,将XML文件读取进内存,形成数据的树结构
2,基于文档对象模型,将文档转化成基于树的层级对象
优点:
形成文档的树对象,对对象进行操作,实现结构改变(增删改查),操作复杂度低,易于理解
缺点:
将文档一次性读取进内存形成持久树对象,内存消耗大,运行效率较低,假如xml文件大,容易造成内存溢出
二,SAX
SAX和DOM一样同属于底层接口,但它的模式和DOM差异较大,互相侧重点不一样,DOM提供增加内存压力来减低操作复杂性,SAX正好相反,提供事件型模式来减低对内存的依赖但不同于DOM的树对象操作,它的操作难度大,不容易掌握。
SAX特点:
1,基于事件型模式,不需要所有xml被加载,
2,事件型模式,对一个个事件进行处理,每次读取一部分数据处理
优点:
对内存消耗小,效率高,事件型处理,拓展性强
缺点:
每次只拥有一部分处理,TAG的处理逻辑(例如维护父/子关系等),文档越复杂,操作难度越大
三,JDOM
JDOM把公共的文档模型变成了java特定的文档模型,它用大量的类取代了底层接口之中的接口,它本质上基于SAX和DOM,它不像基本接口本身不带有解析器,使用SAX2来解析
特点:
1,使用大量的java类,取代了接口,简化了API(把公共的变成java特有的)
2,大量使用集合(Collection)类
优点:
简化了API使开发更加方便
缺点:
1,灵活性较差
2,性能低
四,DOM4J
虽然DOM4J代表了完全独立的开发结果,但最初,它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。从2000下半年开始,它就一直处于开发之中。
为支持所有这些功能,DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。
在添加灵活性、XPath集成和对大文档处理的目标时,DOM4J的目标与JDOM是一样的:针对Java开发者的易用性和直观操作。它还致力于成为比JDOM更完整的解决方案,实现在本质上处理所有Java/XML问题的目标。在完成该目标时,它比JDOM更少强调防止不正确的应用程序行为。
DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的Java软件都在使用DOM4J来读写XML,特别值得一提的是连Sun的JAXM也在用DOM4J.
【优点】
①大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法。
②支持XPath。
③有很好的性能。
【缺点】
①大量使用了接口,API较为复杂。
三,DOM解析
一,DOM的结构
DOM的API结构是按照树文档结构来划分
1,DOM的解析步骤
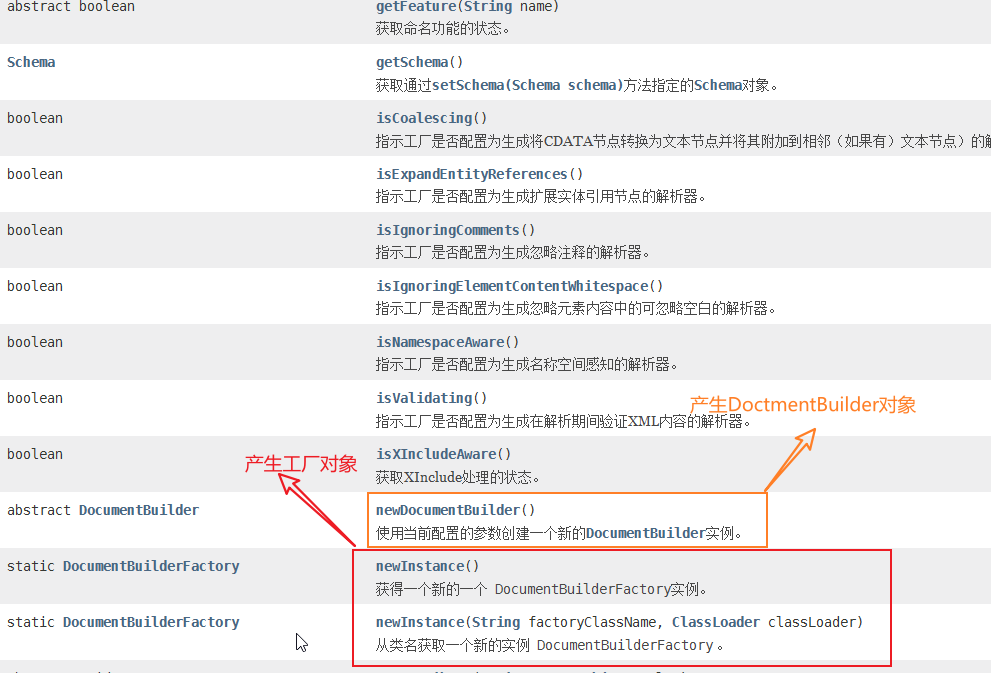
①使用DocumentBuilderFactory创建一个DocumentBuilder工厂
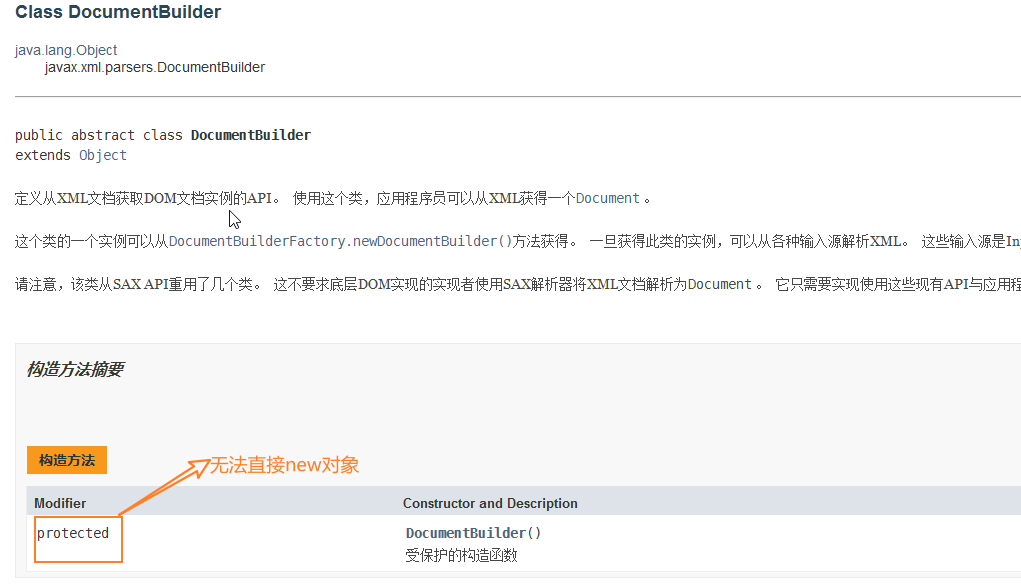
②通过DocumentBuilder创建一个DocumentBuilder对
③通过DocumentBuilder创建Document对象,生成xml树
④解析树结构,得到NodeList的节点列表
⑤遍历NodeList列表得到Node节点
⑥将Node节点转换成Element文档对象元素
⑦操作Element和Attr对象,实现增删改查
2,常用类
1,Document:树构建类,将读取到内存的xml,转化成树
2,Nodelist:将树转换成节点列表
3,Node:树节点
4,Element:文档元素节点
5,Attr:属性对象
二,DOM的API
一,DocumentBuilderFactory和DocumentBuilder
一,DocumentBuilderFactory工厂
构造:无法直接new

方法:
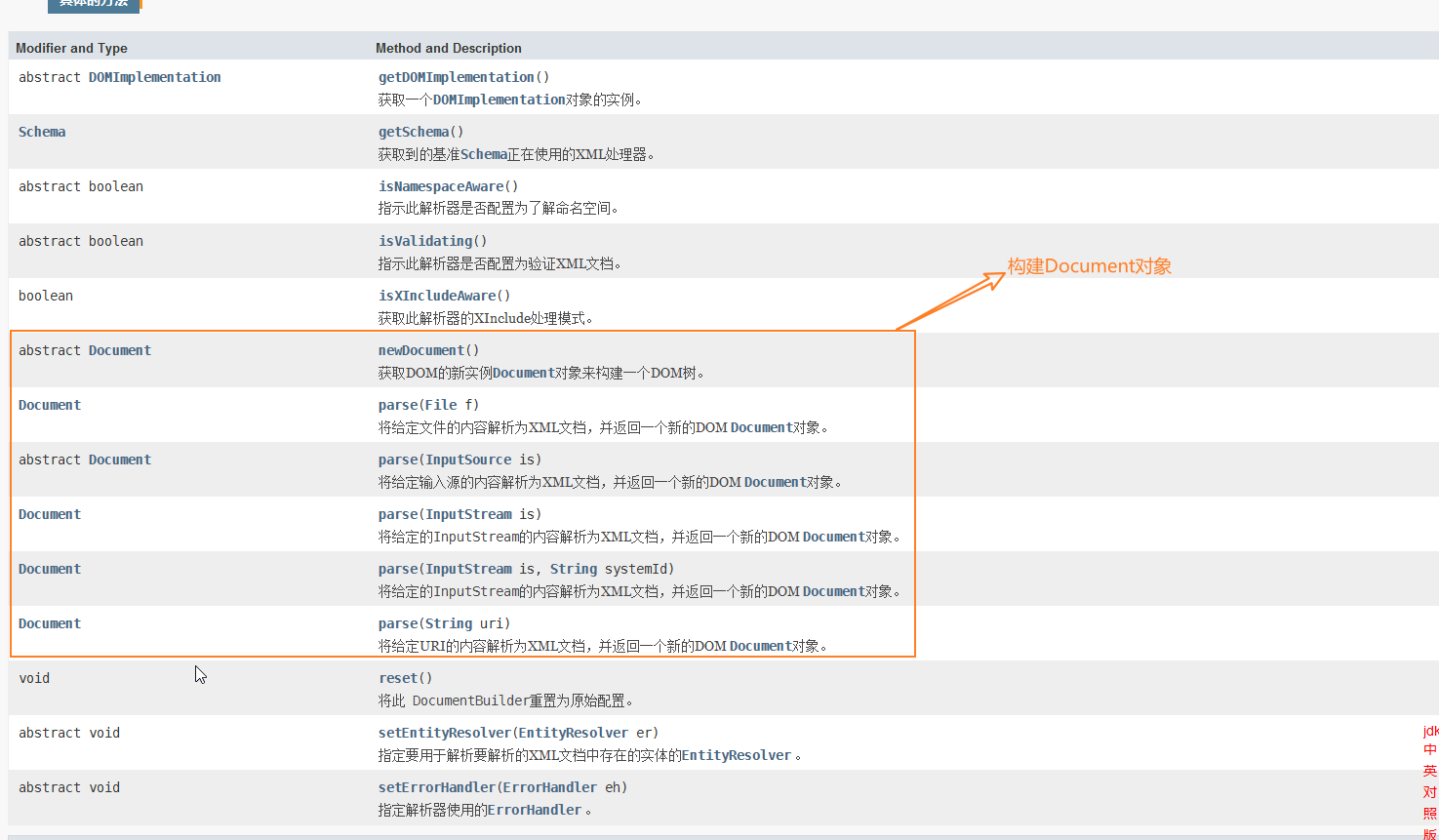
二,DocumentBuilder
构造:访问权限控制,无法直接new
方法:
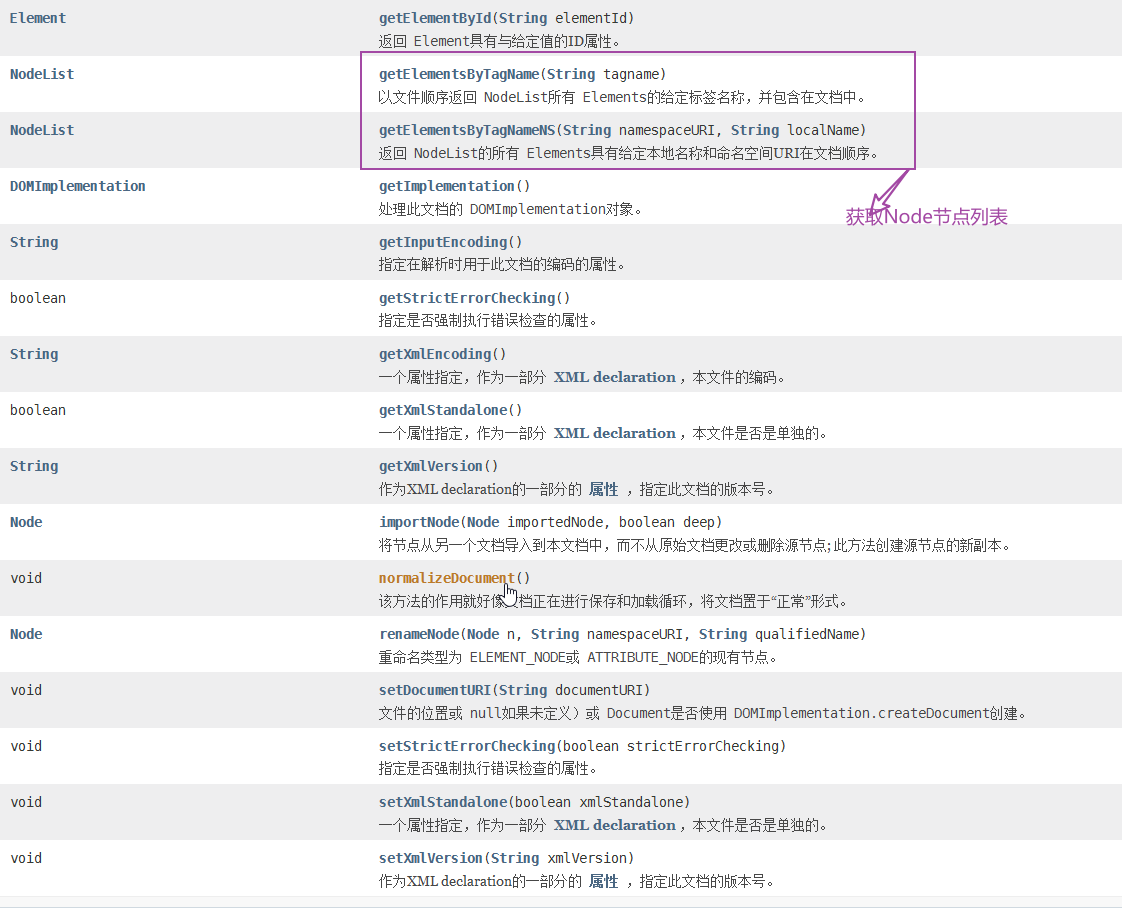
三,Doctment
它没有构造只能通过上面方式创建
方法:


四,NodeList
无构造,本质上是一个对象列表
只有两个方法


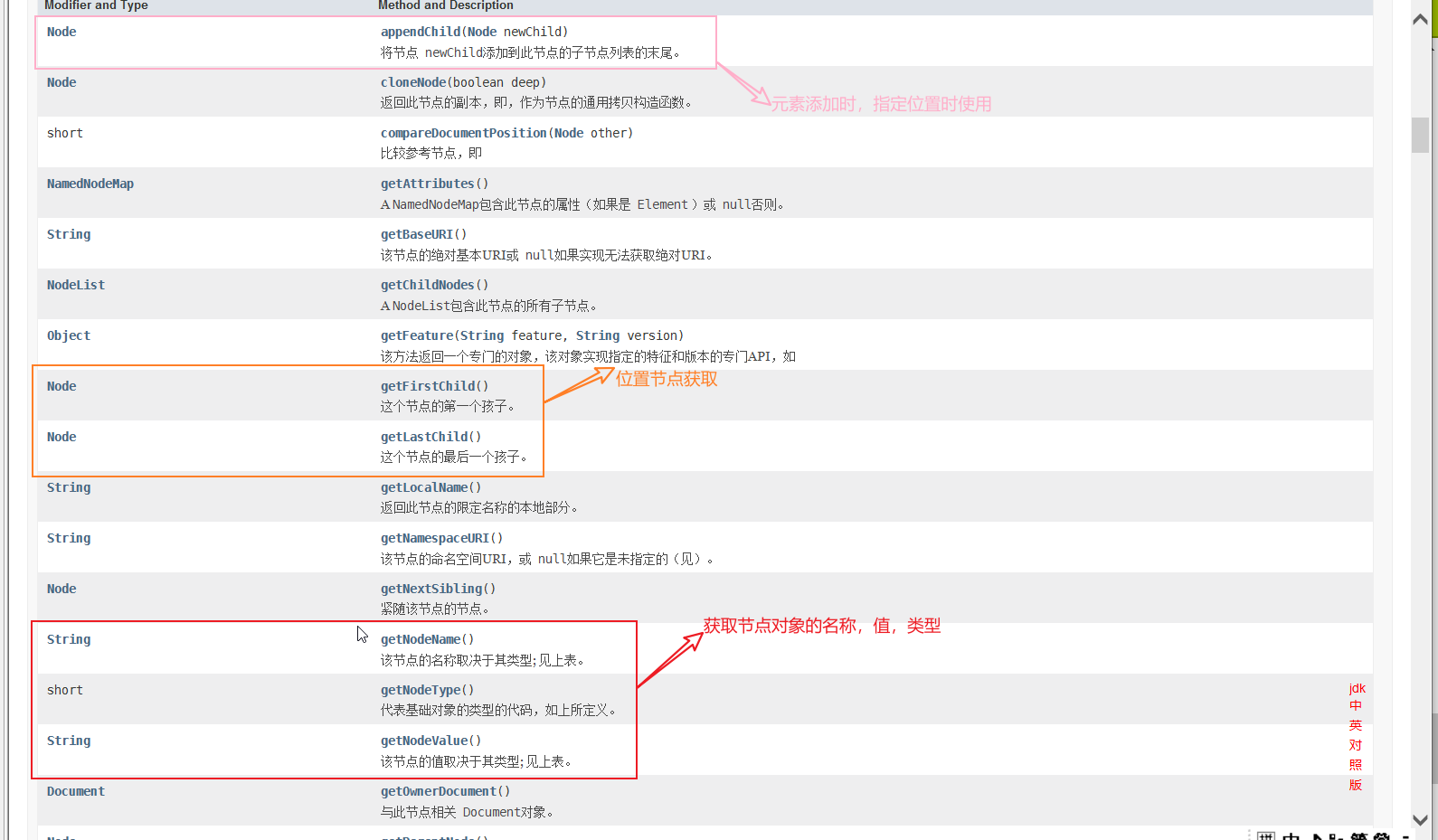
五,Node
无构造
子类:


Node类可以说是DOM的根类
方法:

六,Element
Element的创建:Element一般通过Node的强制性转换产生,它是Node的子类
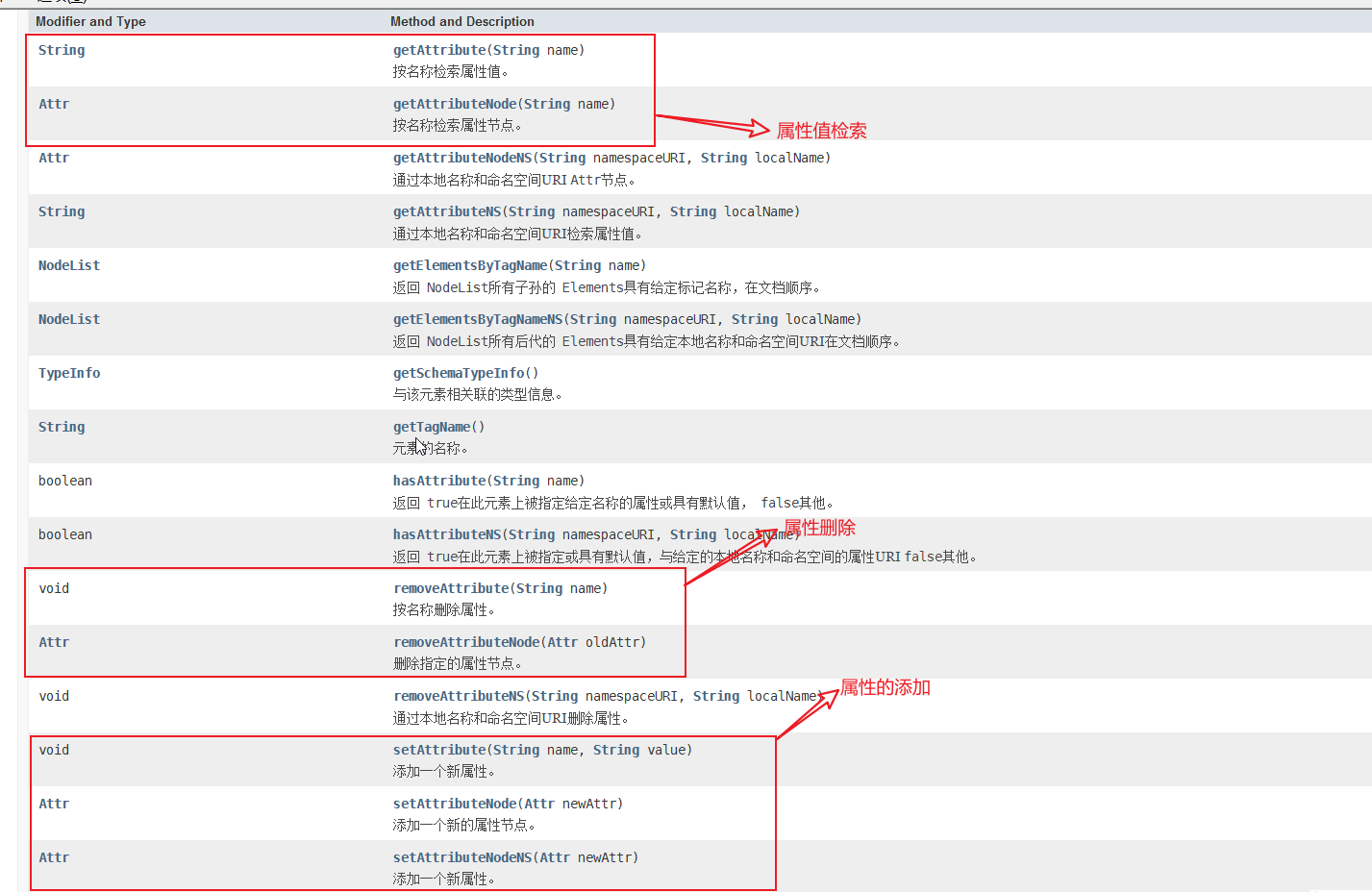
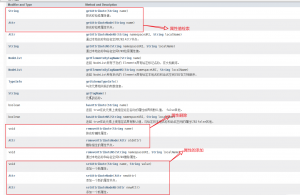
七,Attr
Attr接口表示Element对象中的属性。 通常,属性的允许值在与文档关联的模式中定义
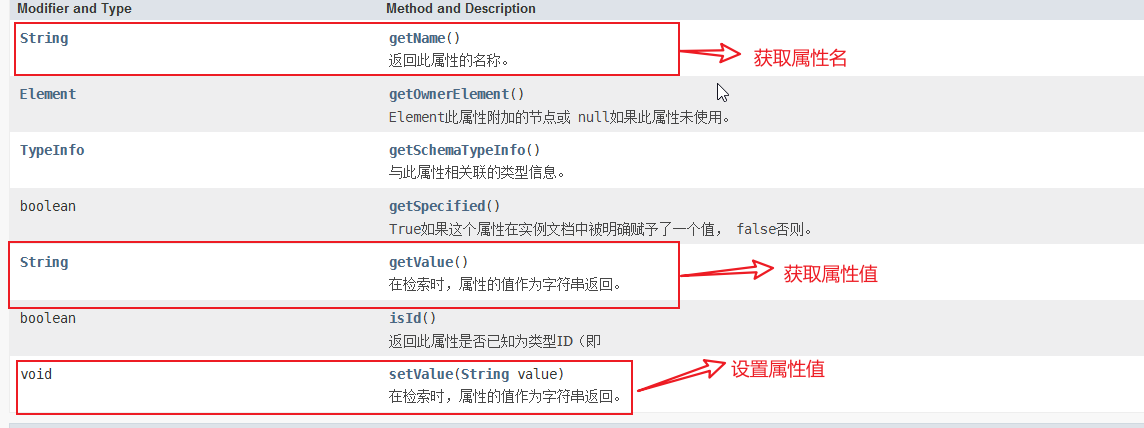
三,DOM对XML文件的增删改查
XML文件:
<?xml version="1.0" encoding="UTF-8"?> <phones> <wql>"节点的值"</wql> <phone name="oppo"> <type name="Rean1"></type> <type name="Rean2"></type> </phone> <phone name="Apple"> <type name="x11"></type> <type name="x10"></type> </phone> <phone name="华为"> <type name="ment10 pro"></type> <type name="P30 pro"></type> </phone>
1,获取Document对象方法
//声明一个Document对象
static Document document;
//xml的解析
//获取Document对象方法
public void getdocument() throws ParserConfigurationException, SAXException, IOException {
//获取DocumentBuliderFactory
DocumentBuilderFactory documentbuliderfactory = DocumentBuilderFactory.newInstance();
//获取DocumentBuilder
DocumentBuilder documentbulider = documentbuliderfactory.newDocumentBuilder();
//Document赋值
document = documentbulider.parse(new File("wql1.xml"));
}
2,DOM查看节点
//解析xml文件,获取直接子元素的name属性值
public void showxml() {
//获取Document的树
NodeList nodelist=document.getElementsByTagName("phone");
//打印node的节点数
System.out.println(nodelist.getLength());
//遍历nodelist
for(int i=0;i<nodelist.getLength();i++) {
//得到节点
Node node = nodelist.item(i);
//把节点转化成元素
Element element = (Element) node;
//获取子节点的属性节点
Attr attr= element.getAttributeNode("name");//属性名
//打印name属性值
System.out.println(attr.getValue());
}}
测试结果:
3 oppo Apple 华为
3,DOM增加节点
//xml节点的添加
public void addxml() {
//创建一个指定类型的元素
Element element = document.createElement("phone");
//为创建的phone元素设置属性
element.setAttribute("name", "小米");
//创建phone的两个type元素
Element element1 = document.createElement("type");
Element element2 = document.createElement("type");
//为type设置属性
element1.setAttribute("name", "K30");
element2.setAttribute("name", "note8");
//将type元素设置成phone的子元素
element.appendChild(element1);
element.appendChild(element2);
//将phone设置成phones的子元素
document.getElementsByTagName("phones").item(0).appendChild(element);
}
测试方法:
@Test
public void test1() throws ParserConfigurationException, SAXException, IOException, TransformerException {
getdocument();//获取Document
addxml();//增加
showxml();//查看增加
}
结果:
4 oppo Apple 华为 小米
4,DOM对XML节点删除
//xml节点的删除
//将苹果节点删除,和修改差不多
public void removexml() {
NodeList nodelist = document.getElementsByTagName("phone");
for(int i=0;i<nodelist.getLength();i++) {
Node node = nodelist.item(i);
Element element = (Element) node;
if(element.getAttribute("name").equals("Apple")) {
//删除Apple
//调用element的父节点,删除子节点
element.getParentNode().removeChild(element);
}
}
}
测试结果:
2 oppo 华为
5,DOM对XML的修改
//xml节点的修改
//吧Apple改成vive
public void alterxml() {
//获取节点列表
NodeList nodelist = document.getElementsByTagName("phone");
//for循环判断name是否apple
for(int i=0;i<nodelist.getLength();i++) {
//获取node节点
Node node = nodelist.item(i);
//转化成Element元素
Element element =(Element)node;
//判断是否name属性为苹果
if(element.getAttribute("name").equals("Apple")) {
//获取Attr属性对象,修改name
Attr attr = element.getAttributeNode("name");
//修改name值
attr.setValue("vive");
System.out.print("修改成功!!");
}
}
6,xml的保存
xml的保存和之前不一样,依赖javax.xml.transfomer包下的类
javax.xml.transfomer的类:
![]()
TransfromFactory工厂类:
构造:权限,不能实例化
![]()
方法:
![]()
Transfromer类:
无构造,只能通过TransfromerFactory创建对象
![]()
Outputkeys类:
该类注意存放字符串常量


输入源Source:

Domsource:
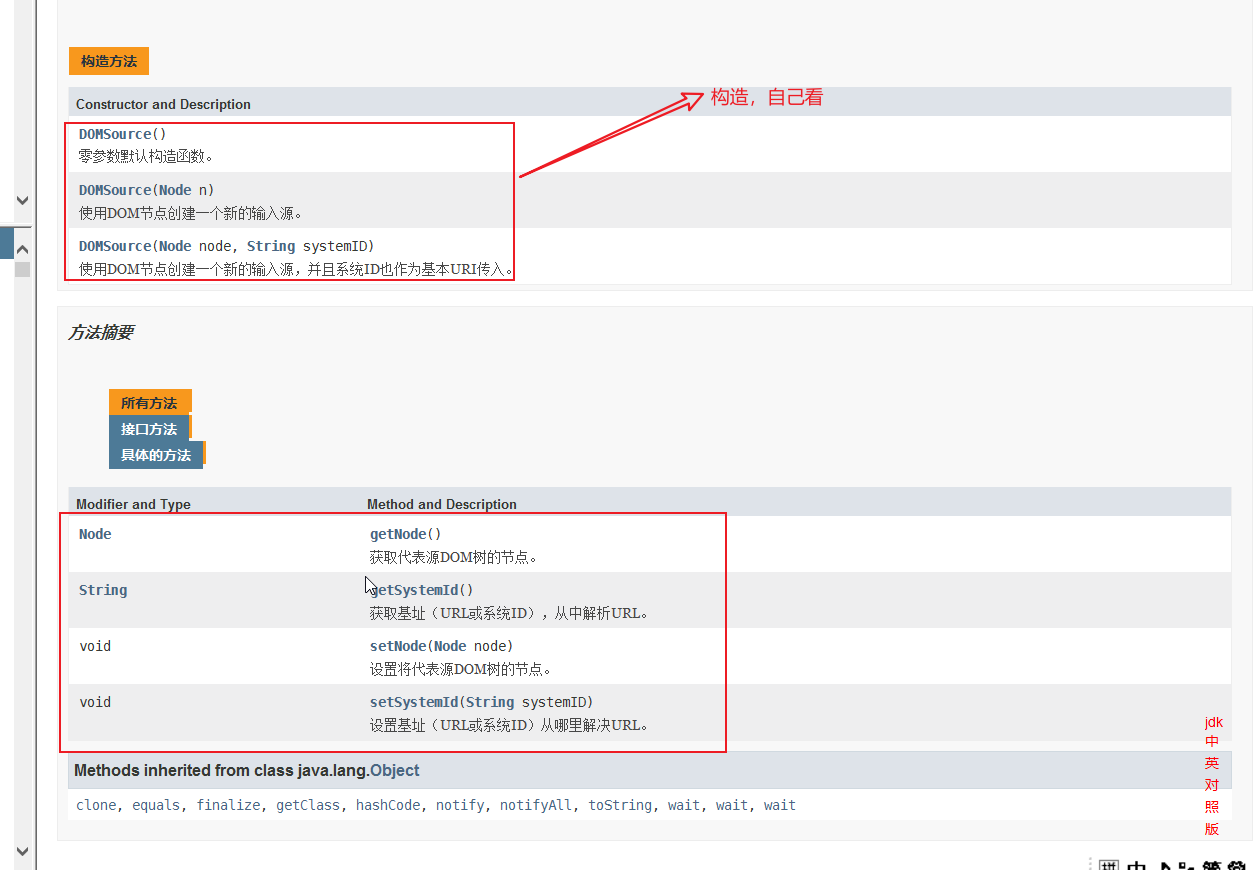
输出源Result:
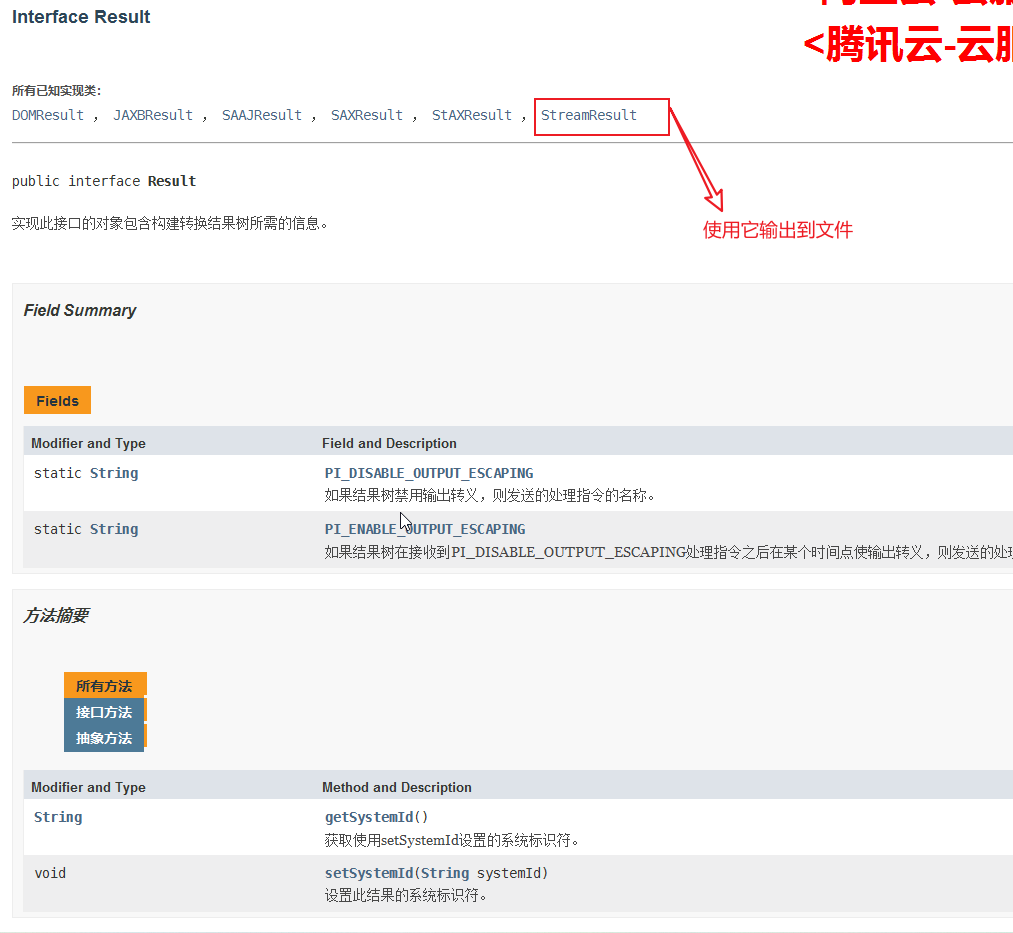
StreamResult:
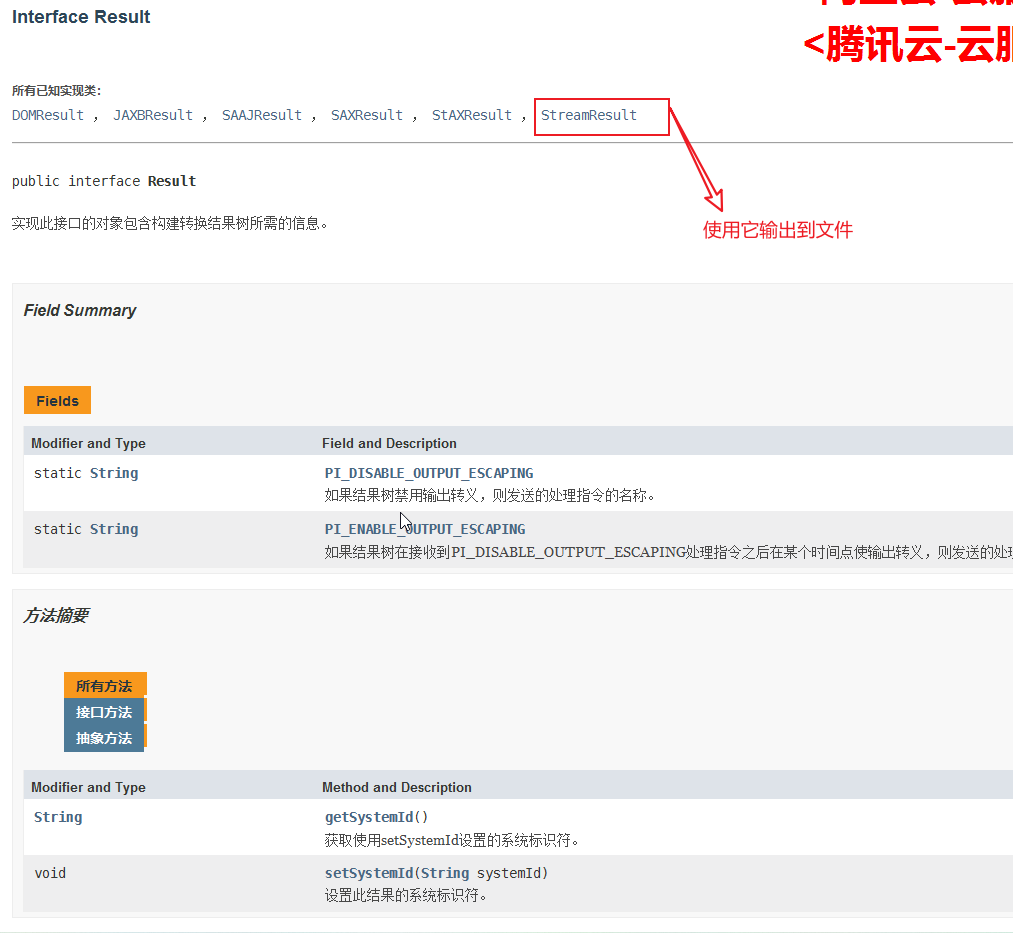
保存:
//xml文件的保存
public void savexml() throws TransformerException {
//获取TransFormer的工厂
TransformerFactory transformerfactory = TransformerFactory.newDefaultInstance();
//通过工厂获取Transformer
Transformer transfomer = transformerfactory.newTransformer();
//设置输入源和输出源(通过Dom源)
DOMSource domsource = new DOMSource(document);
//设置输出源
StreamResult streamresult = new StreamResult("f:\\love.xml");
//通过Transformer写入
transfomer.transform(domsource, streamresult);
}
测试:查看LOVE.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?><phones> <wql>"节点的值"</wql> <phone name="oppo"> <type name="Rean1"/> <type name="Rean2"/> </phone> <phone name="Apple"> <type name="x11"/> <type name="x10"/> </phone> <phone name="华为"> <type name="ment10 pro"/> <type name="P30 pro"/> </phone> <phone name="小米"><type name="K30"/><type name="note8"/></phone></phones>
四,DOM4J框架解析XML
DOM4J的jar包下载:dom4j-1.6.1(WQL).jar
DOM4J和DOM其实差不多都通过Doctdment构建树,Element实现节点元素,但DOM4J使用了大量的集合来,Dom用NodeList来实现遍历,Dom4j用Iterator来实现遍历,
一,DOM4j的包结构和主要类
一,Dom4j包结构

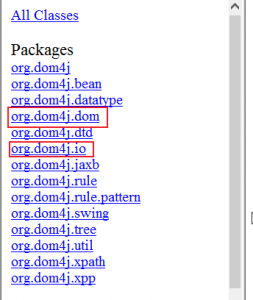
org.dom4j :在Java接口定义了XML文档对象模型并且定义了帮助类。
org.dom4j.bean :dom4j API的实现,允许使用Javabean去存储和检索元素中的数据
org.dom4j.datatype:实现了dom4j API, 提供了对XML Schema Data Types 规范
org.dom4j.dom :实现了dom4j API,提供了对W3C对象模型的支持
org.dom4j.io :当把dom4j 对象写成XML文本流的时候提供了通过DOM和SAX方法的输入输出
org.dom4j.jaxb :其他
org.dom4j.rule :在模式匹配的时允许操作生效时相关的基于实现了完整的XSLT过程模式的XML规则引擎的模式
org.dom4j.rule.pattern:规则的相关匹配模式
org.dom4j.swing:使用树模式或者表格模式时使用的允许方便和dom4j文档和Swing进行整合的适配器集合
org.dom4j.tree :包含了缺省的dom4j对象模型的实现,同时还有一些实现了自己的文档对象模型的有用的基础类
org.dom4j.util:工具类
org.dom4j.xpath:提供了使用XPath库的所需要的核心工具
org.dom4j.xpp:提供了用XMLXPP解析器和dom4j整合在一起所需要的实现类
我们主要使用org.dom4j.io和org.dom4j.dom包下的类
二,主要类
Attribute:Attribute定义了XML的属性
Branch:Branch为能够包含子节点的节点如XML元素(Element)和文档(Docuemnts)定义了一个公共的行为,
CDATA:CDATA 定义了XML CDATA 区域 CharacterData:CharacterData是一个标识借口,标识基于字符的节点。如CDATA,Comment, Text.
Comment:Comment 定义了XML注释的行为
Document:定义了XML文档
DocumentType:DocumentType 定义XML DOCTYPE声明
Element:Element定义XML 元素
ElementHandler:ElementHandler定义了 Element 对象的处理器
ElementPath:被 ElementHandler 使用,用于取得当前正在处理的路径层次信息
Entity:Entity定义 XML entity Node:Node为所有的dom4j中XML节点定义了多态行为
NodeFilter:NodeFilter 定义了在dom4j节点中产生的一个滤镜或谓词的行为(predicate) ProcessingInstruction:ProcessingInstruction 定义 XML 处理指令.
Text:Text 定义XML 文本节点
Visitor:Visitor 用于实现Visitor模式
XPath:XPath 在分析一个字符串后会提供一个XPath 表达式
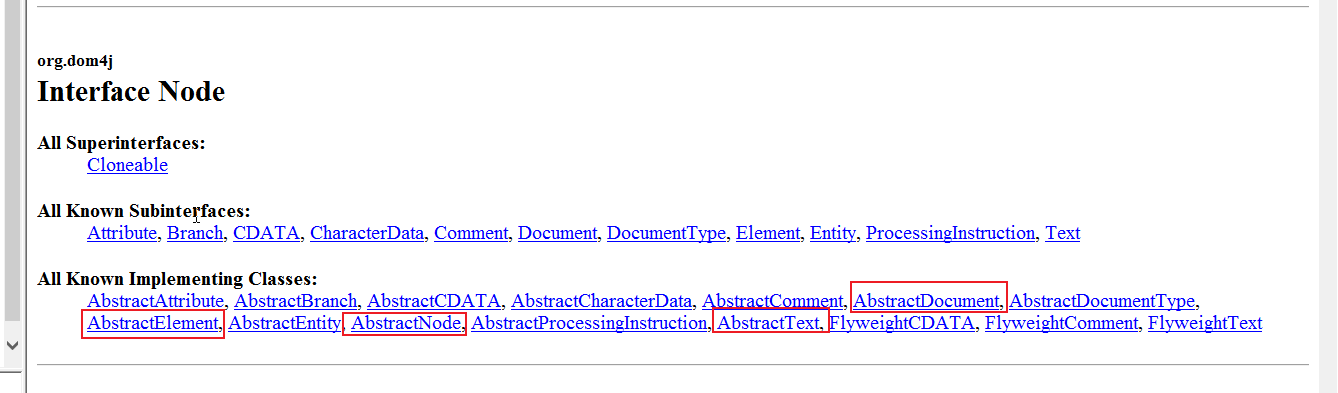
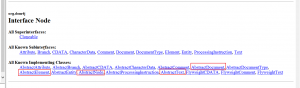
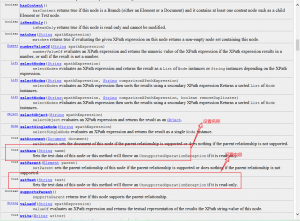
1,Node顶级父类
Text,Element,Document,Comment都是Node的子类
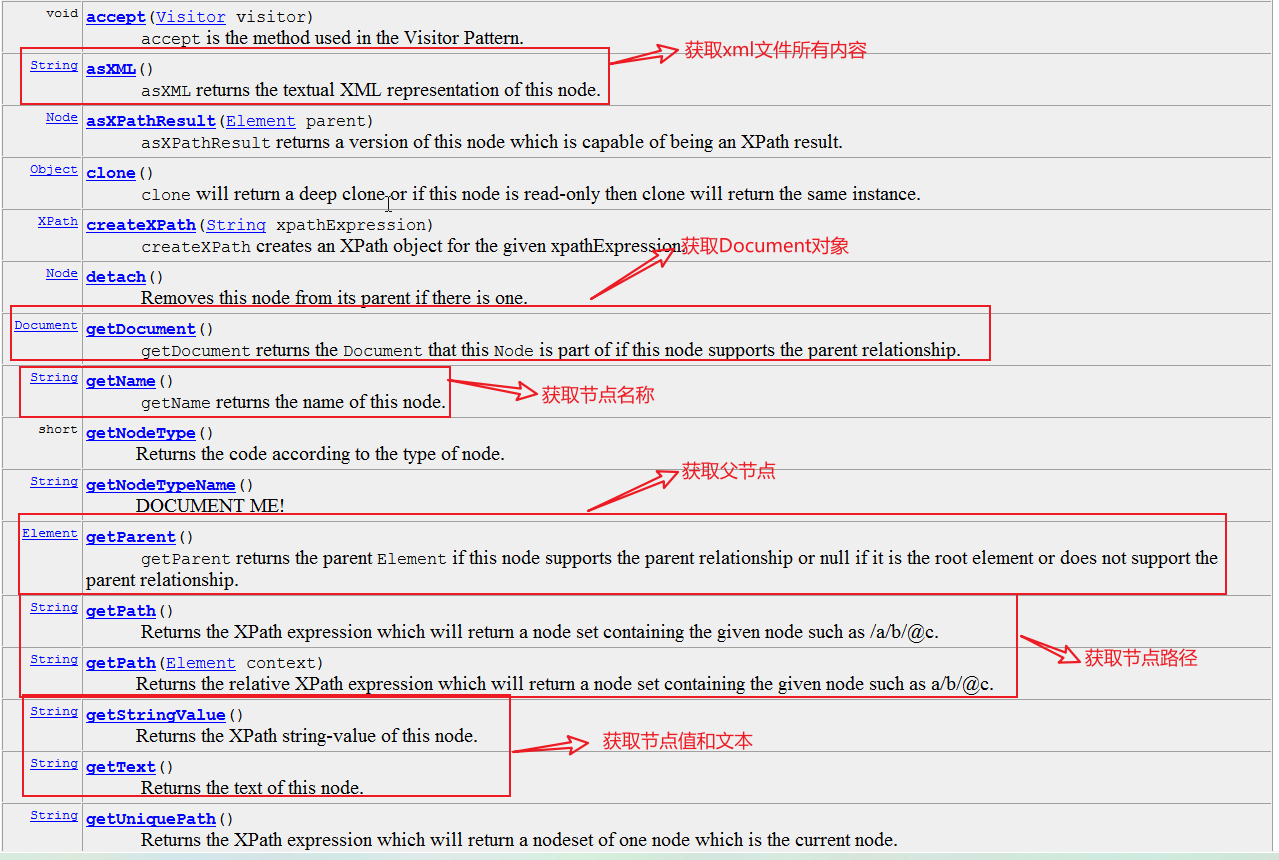
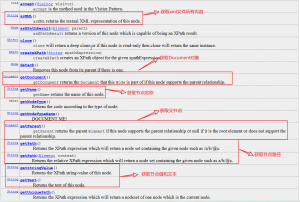
方法:
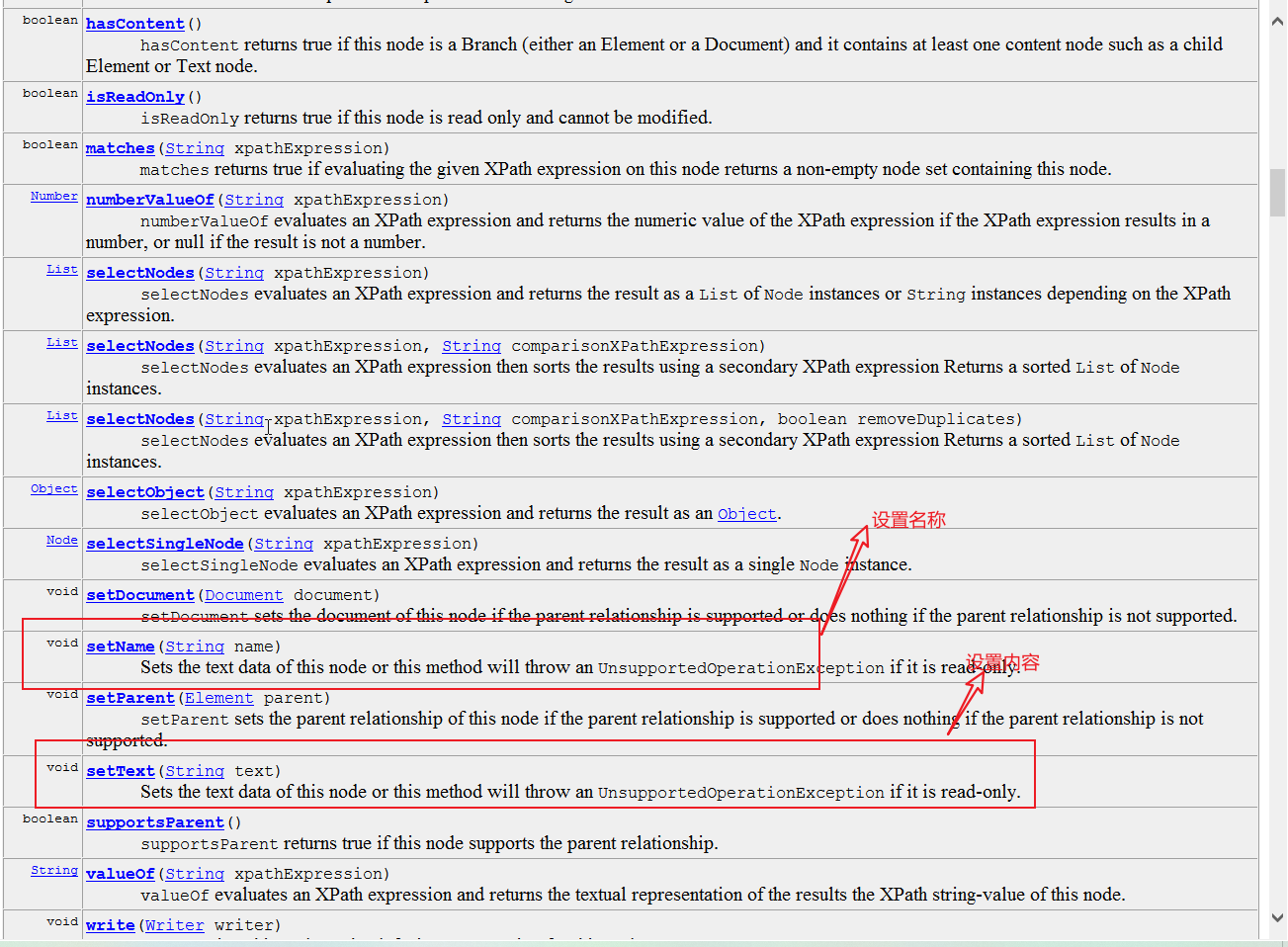
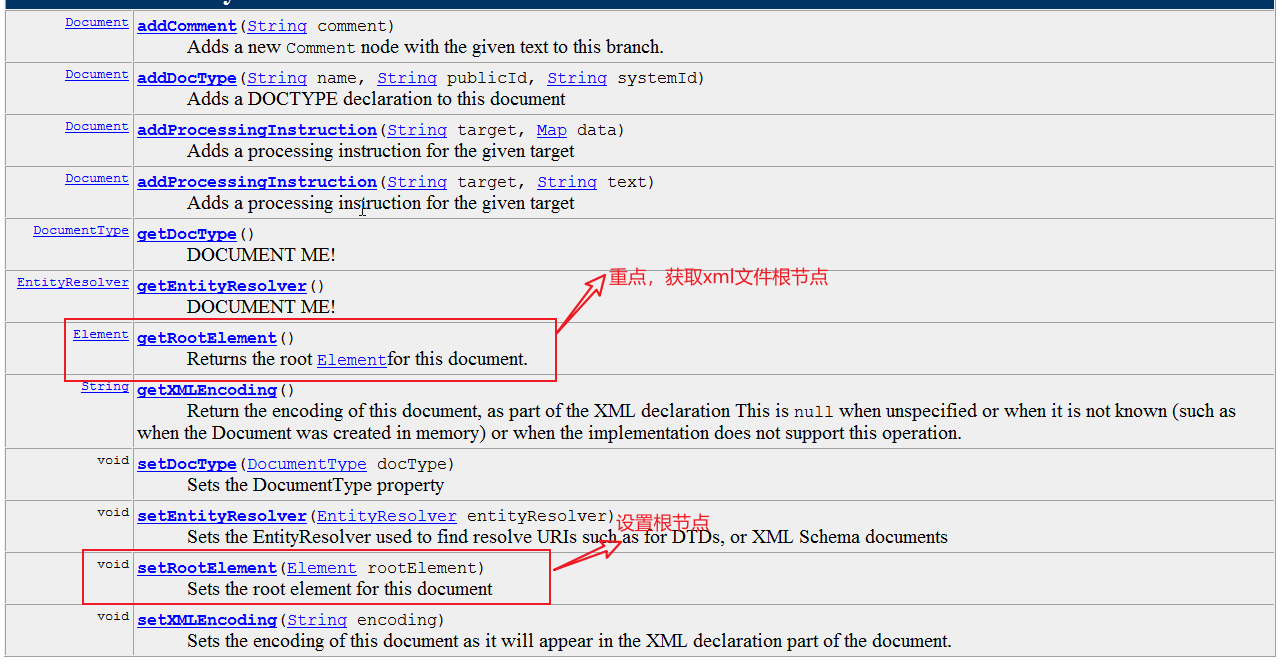
2,Document类
无构造方法,只能读取时产生Documen或者其他方式
方法:

3,Element类
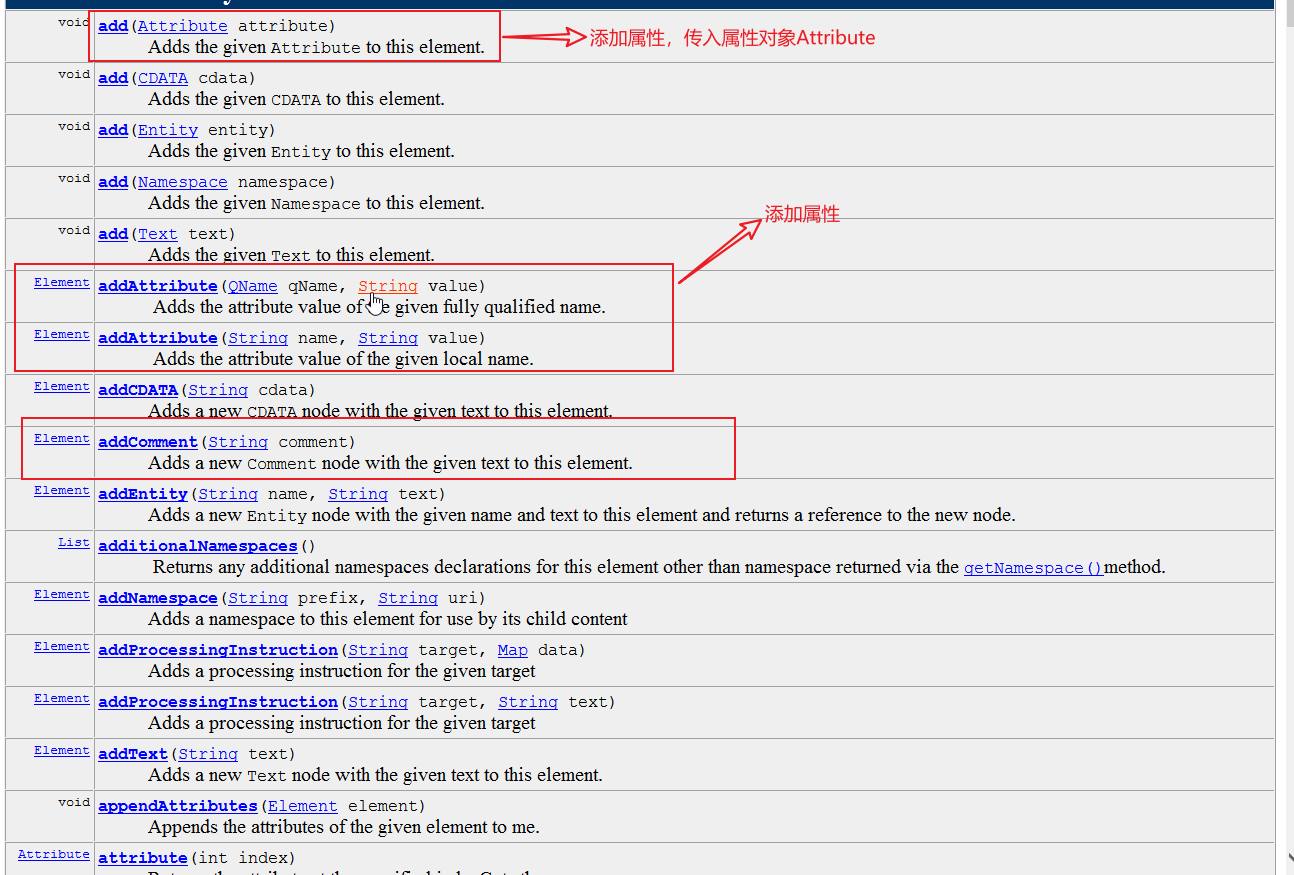
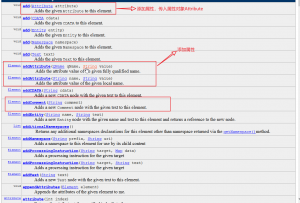
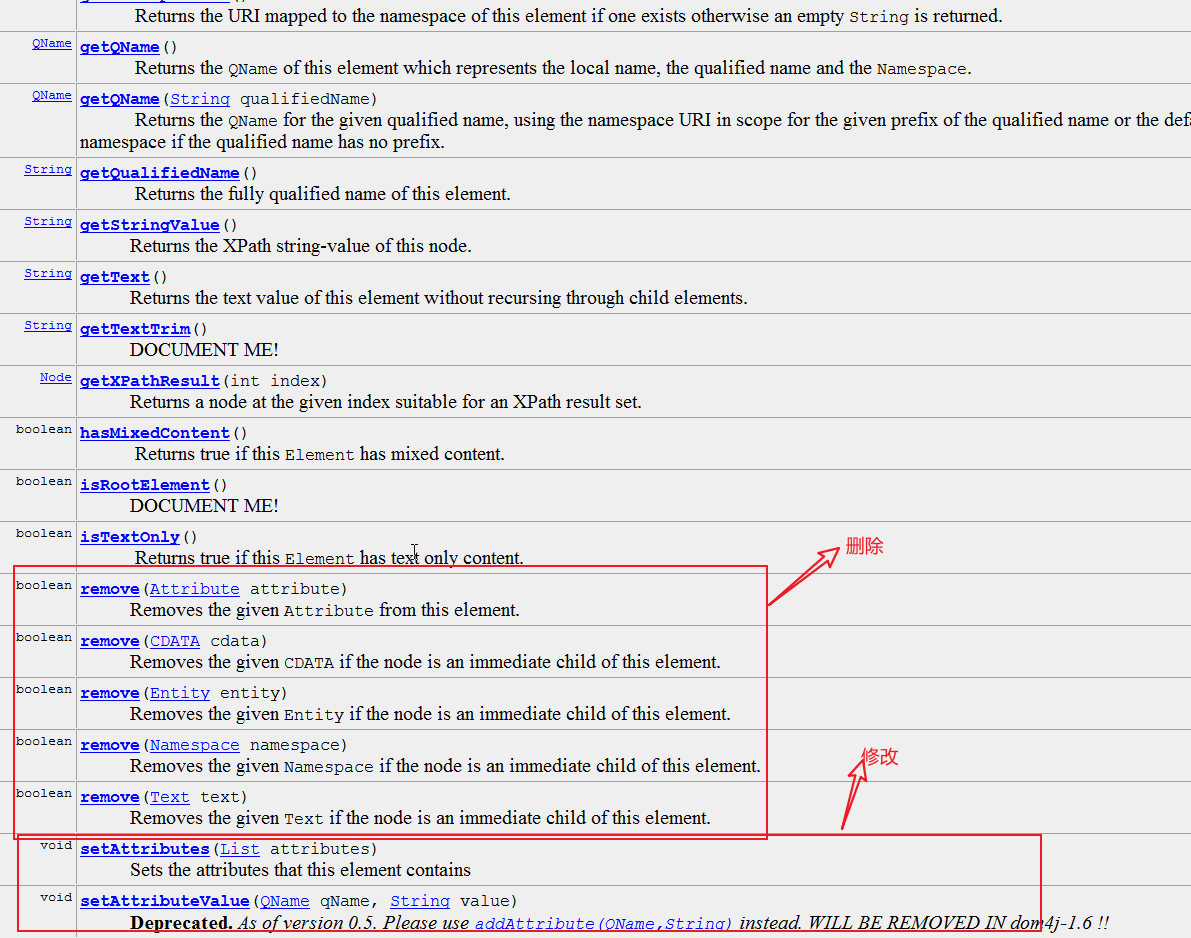
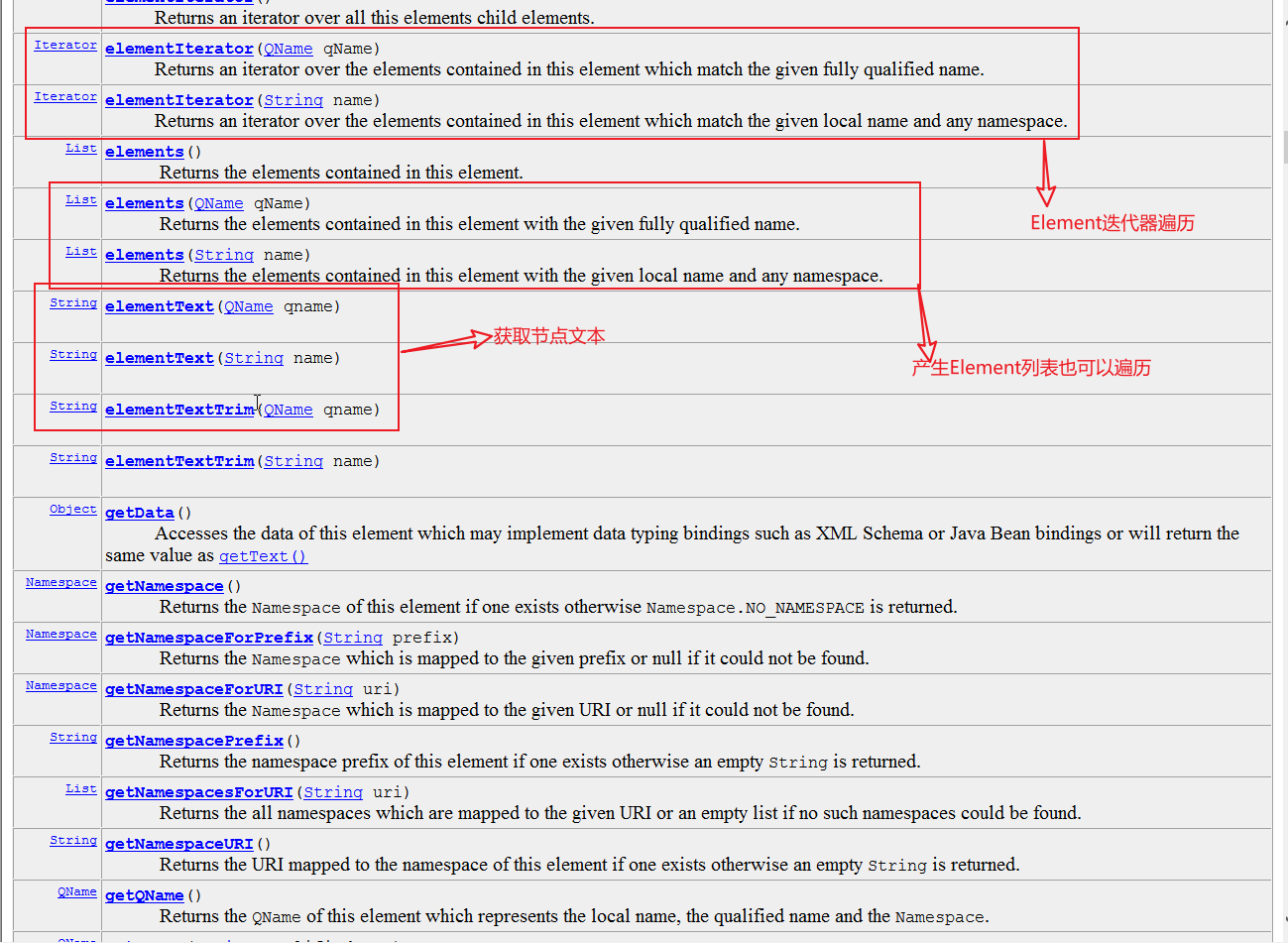
4,Attribute
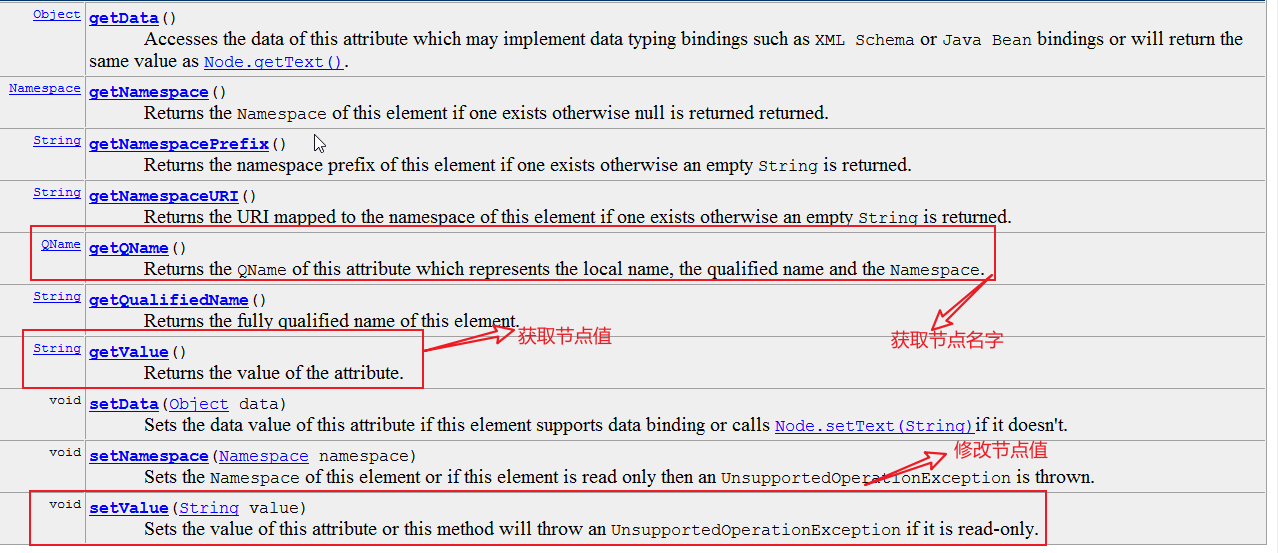
Dom4j的增删改查:
public void parseXml(String args) throws Exception {
//在内存中建立一个saxbuilder文档类型
SAXBuilder saxBuilder=new SAXBuilder();
//根据xmlfile文件创建文档
//Document类是jdom2这个包的,不然会报错叫你转换
Document document=saxBuilder.build(args);
//获得文档根元素
Element rootElement=document.getRootElement();
System.out.println("文档根元素是:"+rootElement.getName());
//获得根元素的所有子元素
List<Element> childList=rootElement.getChildren();
for(int i=0;i<childList.size();i++) {
Element element=childList.get(i);
System.out.println("第"+(i+1)+"个孩子节点是:"+element.getName());
}
//获得第2个孩子的节点
System.out.println("第二个孩子节点的属性名和值start...:");
Element secondChildeElement=childList.get(1);
//获取第二个孩子节点的属性,并迭代遍历输出属性的名称,值和类型
List<Attribute> attributes=secondChildeElement.getAttributes();
for(int i=0;i<attributes.size();i++) {
Attribute attribute=attributes.get(i);
//属性名称
System.out.println("属性名称:"+attribute.getName());
//属性值
System.out.println("属性值:"+attribute.getValue());
//属性类型
System.out.println("属性类型:"+attribute.getAttributeType());
}
System.out.println("第二个孩子节点的属性名和值end。。。");
//如果第二个元素包含有子元素,继续迭代输出
List<Element> sonElements=secondChildeElement.getChildren();
for(int i=0;i<sonElements.size();i++) {
Element ele=sonElements.get(i);
System.out.println("第二个孩子的第"+(i+1)+"个子元素的名和值开始。。。");
System.out.println("子元素名:"+ele.getName());
System.out.println("子元素值:"+ele.getValue());
System.out.println("第二个孩子的第"+(i+1)+"个子元素的名和值结束。。。");
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
jdomRead jRead=new jdomRead();
jRead.parseXml(args[0]);
}
Comments | NOTHING