




一,redis集群的概述
Redis集群概念:redis集群就是对redis的水平复制扩容,即水平扩容N个redis节点,将整个数据库分布式的存储在每个N节点中,每个节点存储总数据量是1/N
分区:redis集群通过分区,来提高一定程度的可用性,假如集群中有一部分节点失效宕机无法进行通讯,集群也可以处理命令(分区在是很多集群的一种容错机制如hadoop集群,hbase集群)
集群主要解决的问题:
1,容量不够:
单台redis容量不够,对redis进行水平扩容,多台redis存储数据,分摊单台存储压力
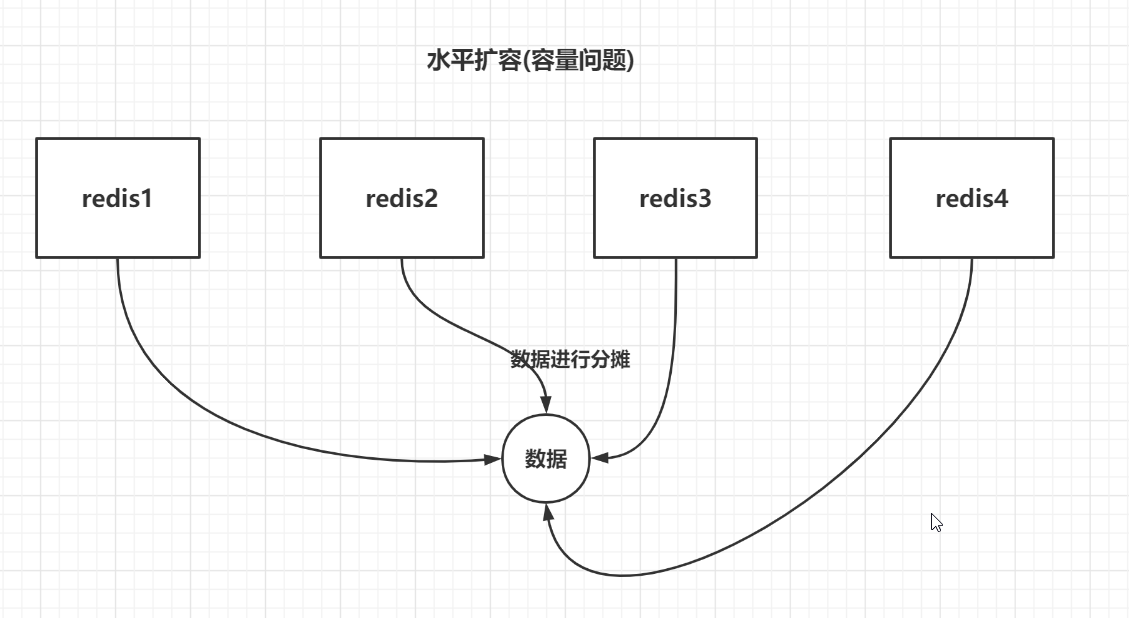
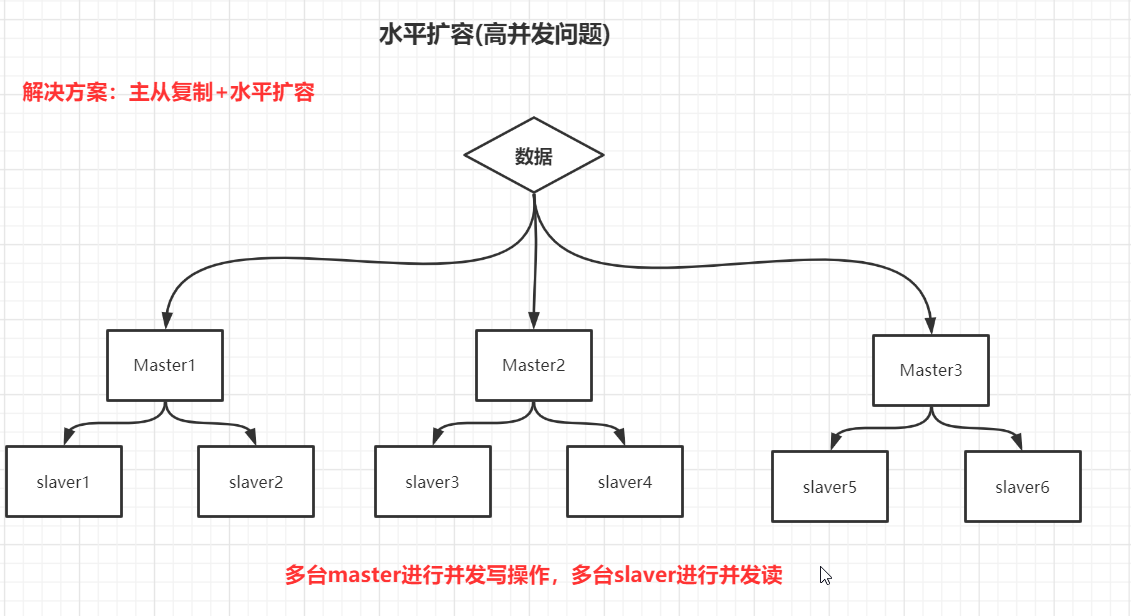
2,并发操作大:
redis主从复制加水平扩容,多台主机既可以进行数据的分摊,也可以进行并发写的压力
容量不够和并发操作的早期解决方案:
代理主机解决(但redis3.0提供无中心化集群配置)
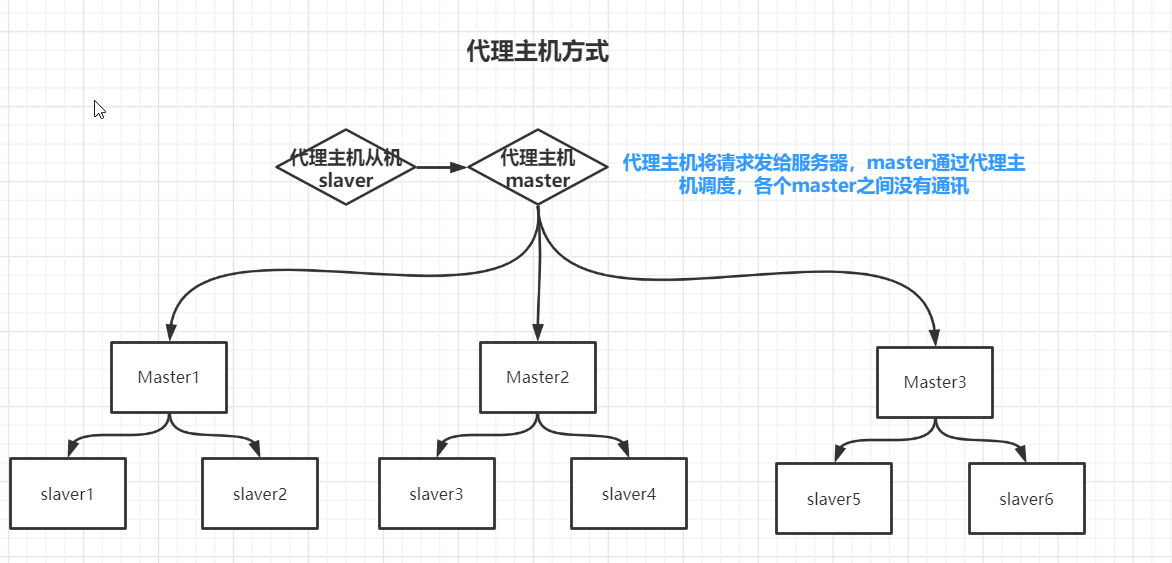
无中心化集群
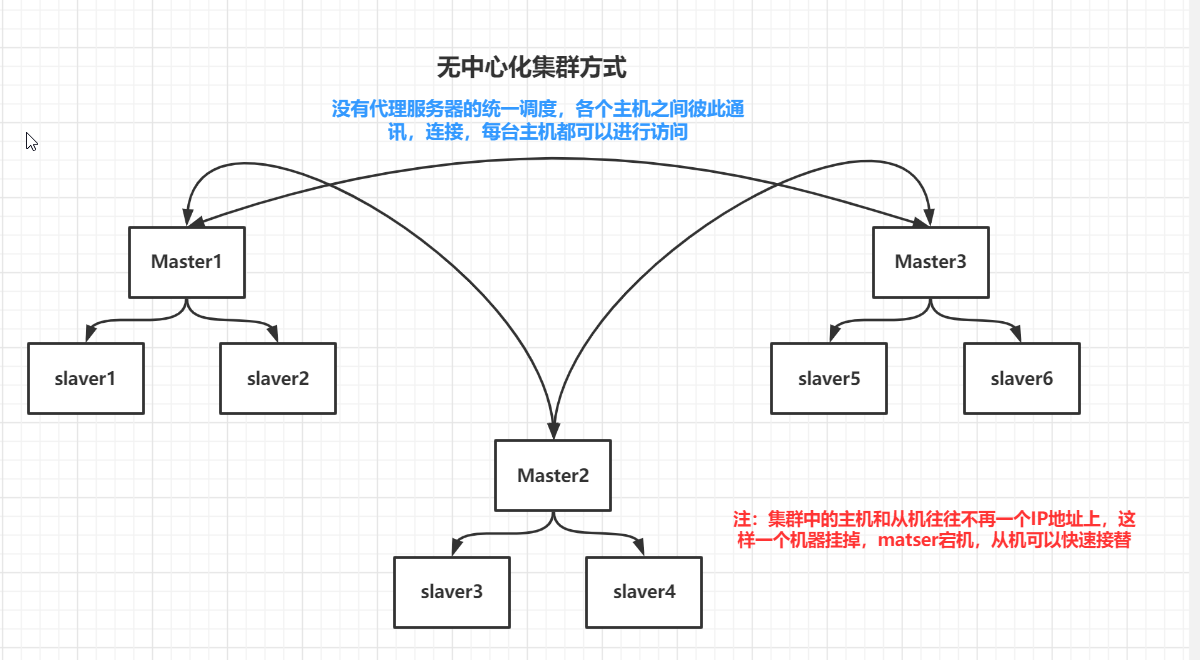
二,redis集群搭建
步骤:
-
删除rdb文件
-
开启redis.conf的cluster集群配置,配置PID,端口,log文件名
-
开启集群
-
连接集群
注:一个redis集群至少有三个主节点
1,删除rdb持久化文件
rm -f *.rdb
2,修改redis.conf配置文件
-
开启集群:cluster-enabled yes
-
设置集群的node文件:cluster-config-file nodes.conf
-
设置集群的超时时间:cluster-node-timeout 1500
-
配置PID文件:pidfile “”
-
配置端口号:port
-
配置rdb文件名:dbfilename “”
-
配置log日志文件:logfile
3,配置完成后单机开启客户端
redis-server 配置文件位置
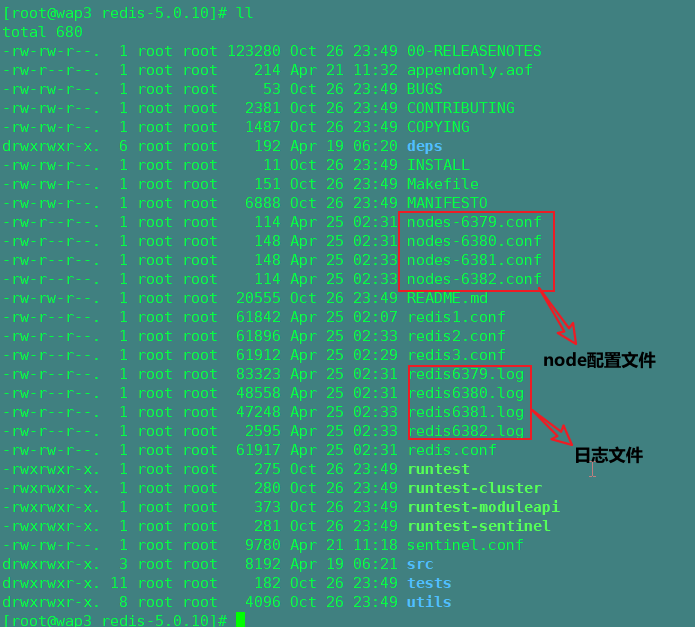
配置成功会出现nodes配置文件:
4,集群模式开启
集群开启需要对redis的单台主机节点做一个合体操作
集群开启命令:redis-cli --cluster cearte --cluster-replicas 1 所有的主机IP:端口号
命令解析:
-
redis-cli 开启客户端
-
cluster-create:创建集群
-
cluster-replicas:副本数(只每一个主机它的从机数)
启动时它会弹出一个确定提示:Can I set the above configuration? (type 'yes' to accept): yes,主从机分配是否满意,yes就行
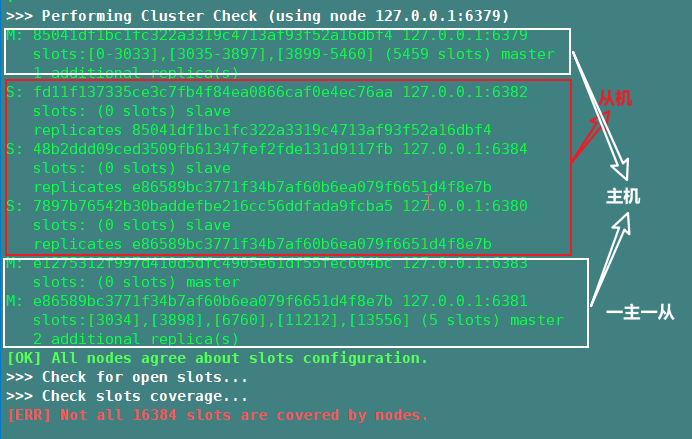
例:启动redis集群
启动命令:redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
5,连接集群
redis集群是无中心化集群,所以随便连那个主机都可以连接到集群
集群连接命令:redis -cli -c -p 端口号 (在普通方式上加一个-c表示连接集群)
客户端查看集群信息命令:cluster nodes
三,集群操作和故障恢复
一,redis集群任何分配节点
redis集群最少要3个主机
cluster-replicas 1:表示集群中每一台主机都有一台从机
分配原则:尽量保证每一个主机运行在不同的IP地址上,每个主机对应的从机也不在一个IP地址上
二,slots插槽
一个Redis集群包含16384个插槽(hash slot),数据库中的每一个键都属于这16384个插槽中的一个集群使用公式CRC16(key) % 16384 来计算键key属于那个slots,其中CRC16(key)语句用于计算键key的CRC16效验和
集群中每一个节点负责处理一部分的插槽
slots的主要作用:slots主要是用来把数据合理分配到各个主机上的,提供判断key的slots值,存储到对应的主机上
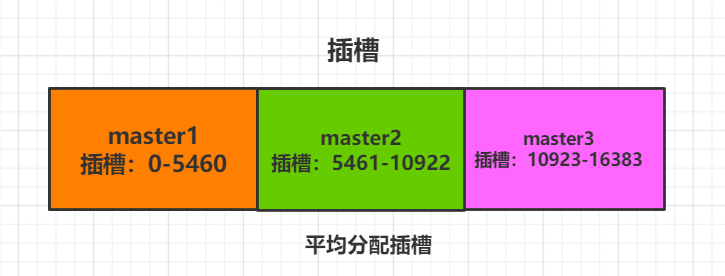
例:假如集群中有三个主机(master1,master2,master3)它的插槽
16384/3=5461(每一个台主机有5461个插槽)
三,集群的操作
集群的操作和单机redis的操作其实大体上差不多,但也有差别
集群操作和单机操作的区别:主要区别是在key的存储上,单机直接存储key,集群要先计算key的slots值来存储到对应的主机上
一,值的存储
1,set key value(单值存储)
先计算key的slots值,确定主机后存储

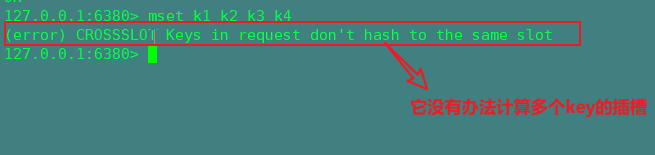
2,mset key1 value1 ……(多值存储)
普通的多值存储会报错:它不能批量的计算key的插槽,需要进行分组存储
分组存储:
格式:mset key{group} value……

二,对插槽的操作
1,获取key的插槽值
命令:cluster keyslot key
1,获取插槽中有几个key
命令:cluster countkeysinslot 插槽值
四,故障恢复
1,如果主节点下线宕机:从节点会自动升为主节点,注:25秒超时
2,主节点恢复后主次关系:主机会变成从机
3,如果所有的某一段插槽的主从节点都宕机,redis的服务是否继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为no,那么该插槽的数据全部不能使用也无法存储,但其他插槽可以使用
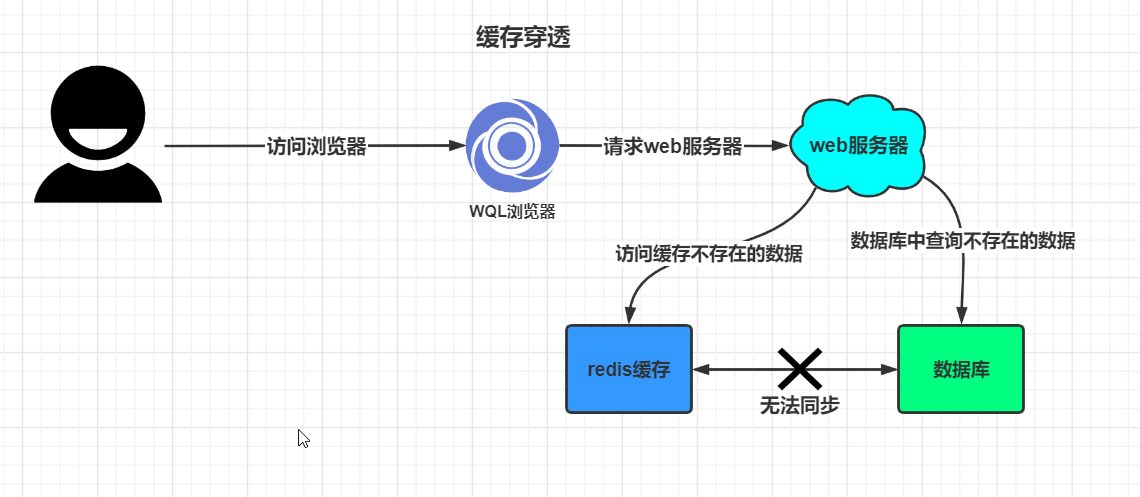
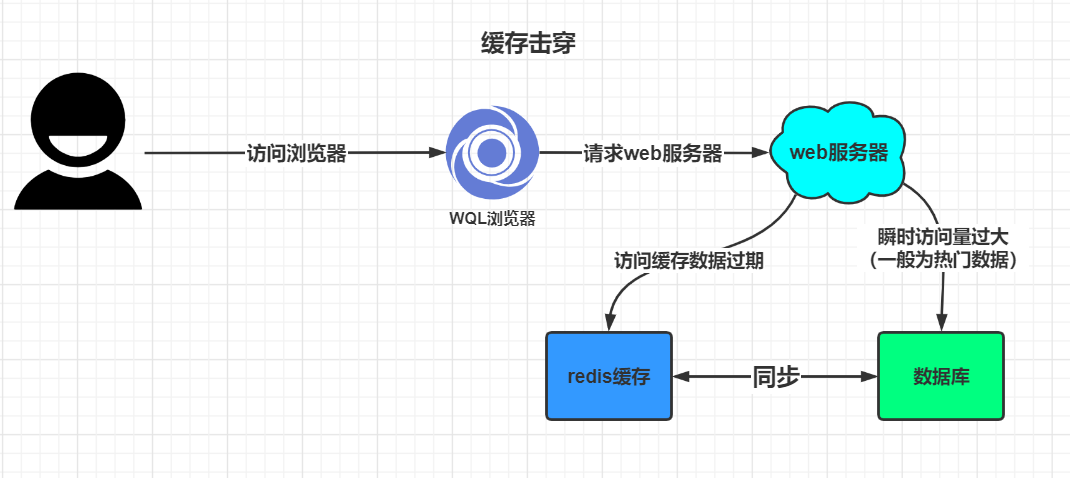
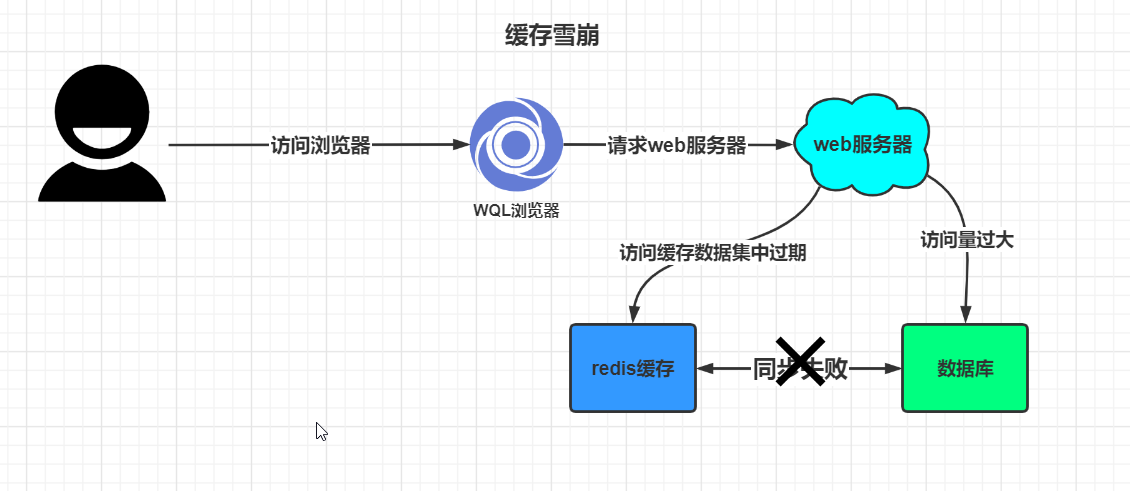
四,缓存穿透,缓存击穿,缓存雪崩
一,缓存穿透
缓存穿透:key对应的数据在数据源中并不存在,每一次针对key的请求从缓存中都获取不到,请求都会压到数据源从数据库中直接获取,从而可以压垮数据库,比如:有一个不存在的用户id获取用户信息,无论从缓存还是数据库都没有,但会在数据库中进行查询,一次假如有N个这样的用户,数据库的访问急剧增大,数据库很有可能直接崩溃
Comments | 1 条评论
66666666