




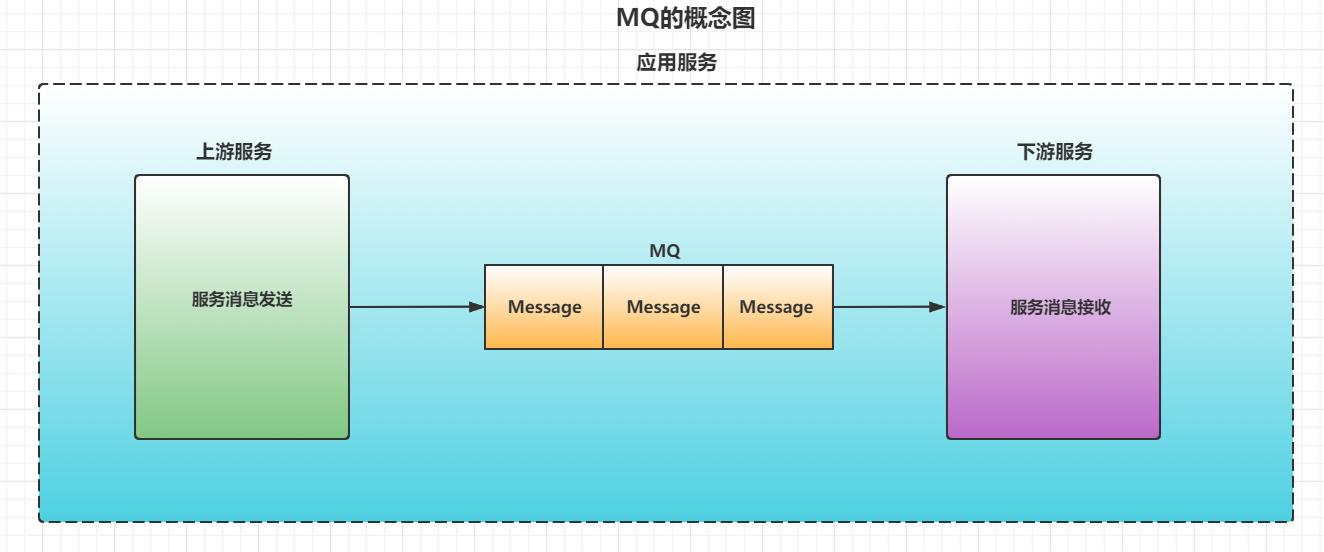
一,MQ的概念
MQ(Message queue)顾名思义他本质上就是队列(FIFO先进先出),只是队列里存放的内容是message,但MQ不仅仅也有队列这一基本属性,它还是一种跨进程的通信机制,用于上下游传递消息,在互联网架构中,MQ是一种非常常见的上下游"逻辑解耦+物理解耦"的消息通信服务,使用了MQ消息的发送只需要依赖MQ,就不再依赖于其他服务
二,MQ的优点(作用)
MQ的作用主要有三个:
- 流量的削峰
- 应用的解耦
- 异步处理
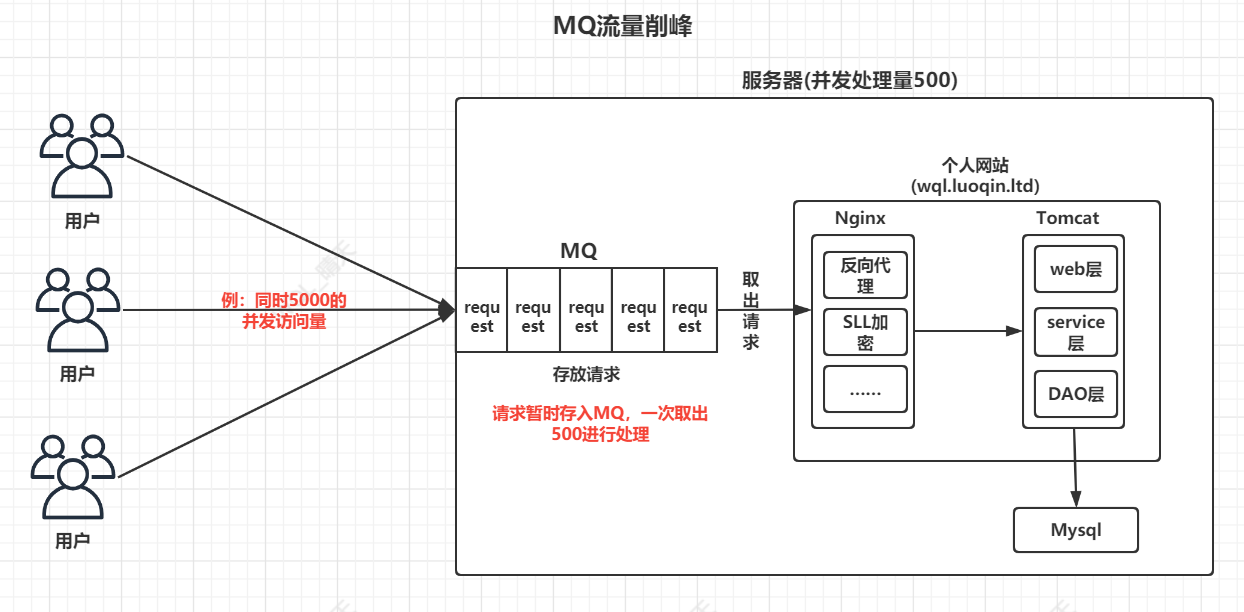
一,流量的削峰
例现在你开发了一个人网站,你把它打成war部署在tomcat中,再通过nginx做代理访问,你单机部署,服务器为1核2GIB,网站一次只能同时处理500个请求,假如你把网站通过B站或其他开源社区分享,突然火了,并发量一次有5000,你的服务器处理不了,直接崩了,或你设置访问限制拒绝了4500的请求,保住了服务器,但丢失了访问量得不偿失,MQ就能很好的防止这种情况的发生,你假如加入了MQ,一次5000请求进入MQ进行消息请求队列暂存,一次取出500进行处理,在某一时刻,请求会被全部处理掉,这样就做到了流量的削峰
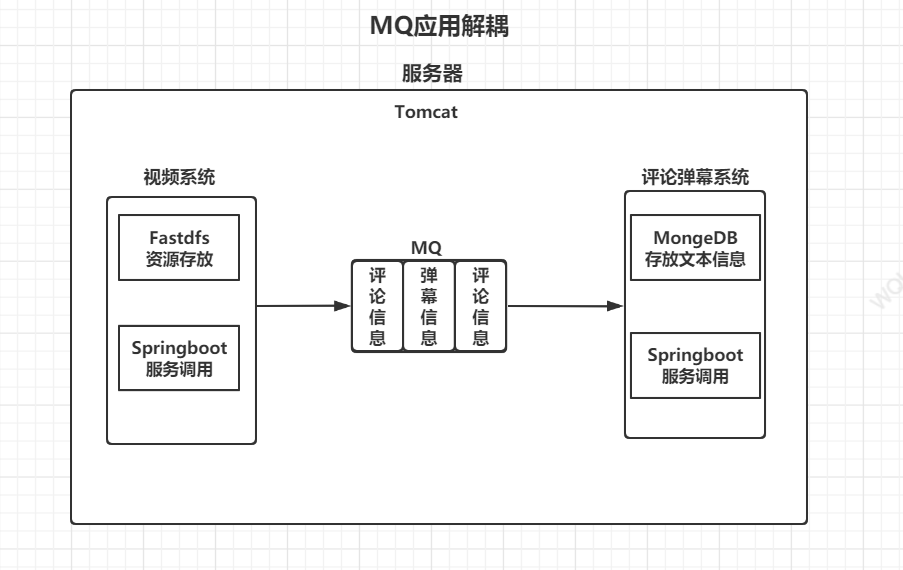
二,应用解耦
现在你的网站访问量激增,用来一定的流量基础,你想把它打造成一个IT分享网站网站而不仅仅是一个个人网站,这个网站有教学视频系统,视频弹幕和评论系统,博客系统,付费资源系统……,这里视频系统依赖于视频弹幕和评论系统,假如其中一个系统环节出现问题都有可能造成这个系统不可用,比如你的评论和弹幕要加敏感词分析功能,在运行系统更新上线的时候,系统会处于不可用的状态,这样用户体验不好,但可以使用MQ进行中间解耦,把用户的评论和弹幕信息暂时放入MQ中,MQ会监督系统完成任务,在系统正常运行时,再做对任务进行处理
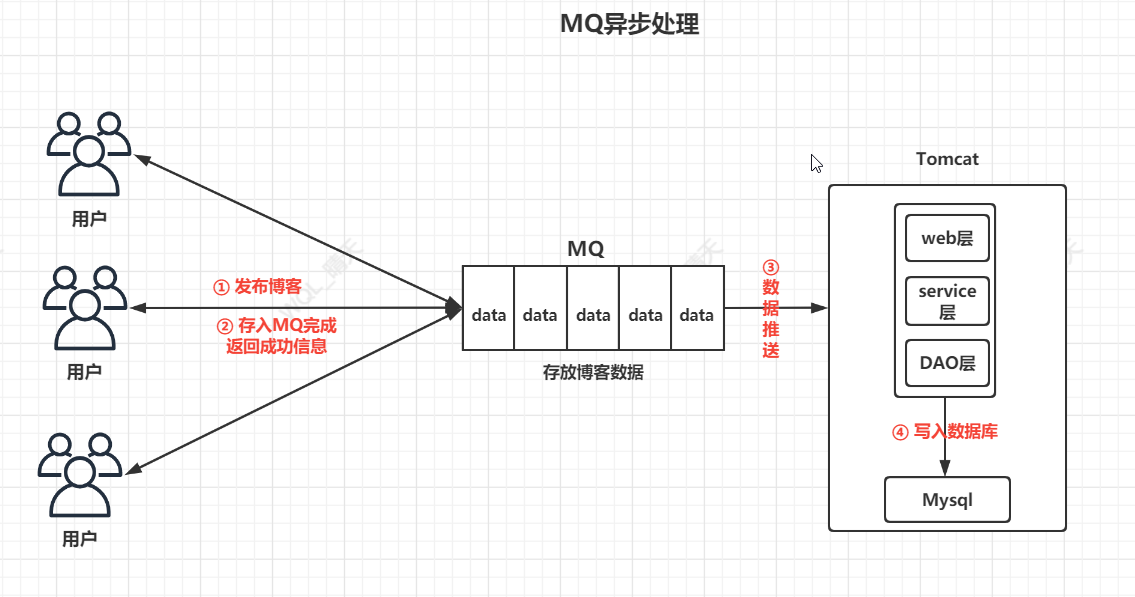
三,异步处理
有一些服务服务调用是异步的,例如博客系统(单体),当用户量很多少,很多用户都对博客进行了发布,发布之后需要等待发布成功的页面,这个页面会调用后台的service层,当博客数据通过DAO写入数据库,就会返回一条成功的json信息,假如是同步时很多用户进行发布,数据库读写需要时间,后面的用户后就会持续的进行等待,直到返回结果为止,这样极大的伤害了用户的体验,使用MQ,可以做到异步处理,用户把博客数据发布时直接进入MQ中(MQ比数据库快几个量级),完成后提升发布成功,MQ进行进行队列的推送写入数据库,做到了异步处理
三,MQ的缺点
MQ的缺点主要有四点:
- 系统可用性降低
- 系统复杂度变高
- 一致性问题
- 重复消费问题(幂等性问题)
- ……
一,系统可用性降低
以前网站的视频功能包含视频系统和弹幕和评论系统,我们只需要维护这两个系统,但使用了MQ进解耦异步,我们还需要维护MQ的可用性,一旦MQ宕机,就会对整个系统造成影响,我们需要保证它的高可用行
二,系统复杂度变高
网站加入MQ会大大增加系统的复杂度,提高维护成本,以前系统间远程同步调用,现在通过MQ进行异步调用,如果保证消息不背重复消费?怎么处理消息不丢失?怎么保证消息的有序性?这些都是面临的问题
三,一致性问题
视频系统处理业务,通过MQ发生给弹幕,后台统计等系统,如何保证它们都能全部处理成功,保证消息处理的一致性?
四,MQ的分类
MQ主要有四大具体实现:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
一,ActiveMQ
ActiveMQ是出现最早的MQ,现在开发使用频率很少,社区维护也越来越少
优点:单机吞吐量万级,时效性毫秒级,可用性高,基于主从架构实现高可用,消息的可靠较高,较底概率丢失数据
缺点:官方社区对再ActiveMQ5.0以后的版本,维护越来越少,高吞吐量场景较少使用
二,Kafka
Kafka消息中间件主要再大数据领域用,与Spark一起使用做数据的推送和分析处理,它的TPS有百万级,在数据的采集,传输,存储发挥着举足轻重的作用,是当前大数据领域最流行的消息中间件
优点:性能优越,单机写入TPS约百万条/秒,最大的优点就是吞吐量高,时效性也非常好,Kafka是分布式的,适用于分布式场景,一个数据多个副本,少数的机器宕机,不会丢失数据,不会导致不可用,消费者采用Pull发生获取消息,消息有序,通过控制能够保证所有数据只能被消费一次,有较好第三方kafka web管理界面Kafka-Manager,在日志领域比较成熟,在大数据领域的实时计算以及日志采集被大规模使用,被多个公司和多个开源项目使用
缺点:Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长,使用短轮询方式,实时性取决于轮询的间隔时间消费失败不支持重试,支持消息顺序,但是一台代理宕机后,就会产生消息乱序
三,RocketMQ
RocketMQ是阿里的开源项目,用java语言实现,在设计时参考了Kafka,并做出了一些改进,被阿里广泛应用于订单,交易充值,流计算,消息推送,日志流处理,binglog分发等场景
优点:单机吞吐量十万级,可用性非常高,适用于分布式架构,消息可以做到0丢失,MQ功能较为完善,拓展性较好,支持10亿级别的消息堆积,不会因为堆积导致性能下降,源码是java我们可以阅读源码,学习架构
缺点:支持的客户端语言不多,目前是java及C++,其中C++还不成熟,,社区活跃一般,没有在MQ核心中实现JMS等接口,有些系统要迁移需要大量修改代码
四,RabbitMQ
Rabbit是2007发布,在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一
优点:由于erlang语言的高并发性,性能较好,吞吐量到万级,MQ功能比较完备,健壮,稳定,易于,跨平台,支持多种语言如:python,java,JMS,C,PHP,Ruby等,支持AJAX文档齐全,开源提供的管理界面非常好,社区活跃度高,更新频率高
缺点:商业版收费,学习成本高
五,MQ的对比和选择
|
ActiveMQ
|
Kafka
|
RocketMQ
|
RabbitMQ
|
|
| 公司/社区 | Apache |
Apache
|
阿里
|
Rabbit
|
|
开发语言
|
Java
|
Scala&Java
|
Java
|
Erlang
|
|
协议支持
|
OpenWire,STOMP,REST,XMPP,AMQP
|
自定义协议,社区封装了http协议支持
|
自定义
|
AMQP,XMPP,SMTP,STOMP
|
|
客户端支持语言
|
Java,C,C++,Pythhon,PHP,.Net…等
|
官方支持java,社区支持多种API,如:PHP,Python…等
|
Java,C++(不成熟)
|
官方支持Erlang,Java,Ruby等几乎所有语言
|
|
单机吞吐量
|
万级(最差)
|
十万级(次之) | 十万级(最好) | 万级(其次) |
|
消息延迟
|
毫秒级 |
毫秒以内
|
毫秒级 |
微秒级
|
|
功能特性
|
老牌产品,成熟度高,文档较多
|
只支持主要的MQ功能,主要针对对大数据领域
|
MQ功能完备,拓展性佳
|
并发能力强,性能极好,延迟底,社区活跃高,管理界面丰富
|
MQ的选择:
1,Kafka:适合产生大量数据的互联网服务的数据收集业务,大数据项目可以采用,大型公司也建议采用,如果有日志收集功能建议首先
2,RocketMQ:天生为金融互联网领域而生,对应可靠性要求很高的场景,尤其是电商项目的订单和扣款,以及业务的削峰,大量交易涌入时无法处理时建议使用RocketMQ
3,RabbitMQ:本身性能较高,如果数据量没有那么大,中小公司优先选择功能比较完备的RabbitMQ
Comments | NOTHING