




一,select基础查
select语句的两种格式:
- select 算术表达式(函数) :进行运算
- select 参数 from table:进行表查询
1,select进行运算
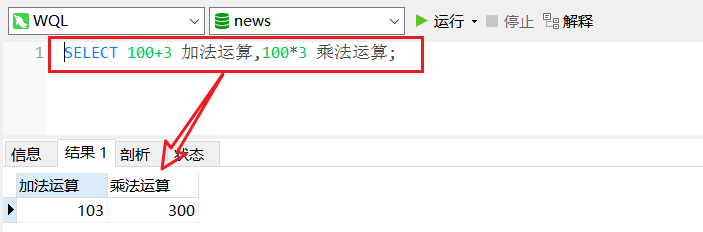
SELECT 100+3 加法运算100*3 乘法运算
2,select表查询
参数:
- *:所有字段
- 字段名
- 函数数
- 算术表达式
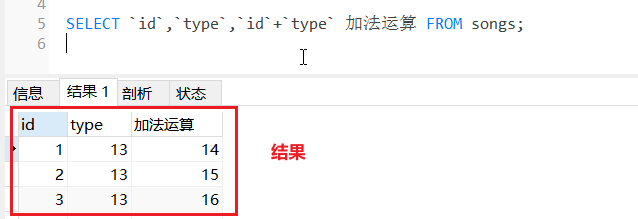
例:查询指定的id和type字段,并将两个字段相加且取一个加法运算的别名
SELECT `id`,`type`,`id`+`type` 加法运算 FROM songs;
二,列的别名
别名顾名思义就是重命名一个列
- 便于技术
- 紧跟列名,也可以在列名和别名之间加入关键字AS,别名可以使用双引号,以便在别名中包含空格或特殊字符区分开来
注:建议别名简短,见名知意,AS一般省略,在书写时用空格代替
例:
SELECT `name` "歌曲名称",`singer` AS "歌手名称" FROM songs;

三,数据去重
数据去重使用DISTINCT关键字进行去重
DISTINCT有两种方式:
- 单列去重查询
- 多列去重查询
1,单列去重查询:
SELECT DISTINCT `type` FROM songs; #对类型进行去重
2,多列去重查询
多列去重有两种情况:
- SELECT DISTINCT `字段1` ,`字段2` FROM ……:这个是对两个字段都进行去重
- SELECT `字段1` ,DISTINCT `字段2` FROM ……:这个是只对字段2进行去重,字段一没有进行去重
例:
① 对name和type字段进行全部去重
SELECT DISTINCT `type`,`name` FROM songs;
② 对type字段进行去重,name不去重
SELECT `type`,DISTINCT `name` FROM songs;

注:多列去重在查询中一般是没有啥意义的,去重多用于单列子查询中
四,where数据的过滤
语法:
SELECT 字段1,字段2 …… FROM 表名 WHERE 过滤条件
- 使用WHERE子句,将不满足条件的行过滤掉
- WHERE子句紧随FROM子句
例:查询type值大于13
SELECT * FROM songs WHERE `type`>13;
二,分页和排序查询
一,排序查询
MySQL使用ORDER BY进行排序:
- ASC(ascent):升序(默认)
- DESC(descent):降序
注:Order和where一起使用,order在where后面
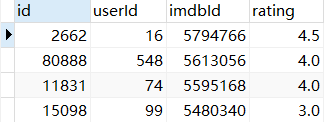
1,单列排序
#降序 SELECT * FROM users_resulttable ORDER BY imdbId DESC;
2,与WHERE配合使用
#HWERE和ORDER一起使用,ORDER必须在WHERE后面 SELECT * FROM users_resulttable WHERE rating IN(4.0) ORDER BY imdbId;
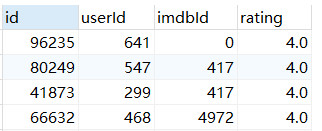
3,ORDER使用别名进行排序
SELECT userId ID,imdbId IM,rating RAT FROM users_resulttable ORDER BY IM DESC;
在WHERE是不能使用别名的,因为一个SELECT查询语句最先执行就是WHERE条件判断,在执行SELECT,最后才进行ORDER,所以在WHERE使用别名是读取不到的

4,多级排序
格式:ORDER BY 字段一,字段二……
先按照字段一进行排序,排序完成之后,在将同一个字段一中的字段二进行排序
注:在进行多列排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序,如果第一列数据中的所有值都是唯一的,将不再对第二列表进行排序
例: SELECT * FROM users_resulttable ORDER BY rating,imdbId DESC;
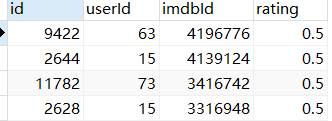
二,分页查询
一,分页的使用
分页每次查询只显示一段数据,在应用的很多场景中使用,MySQL提供了Limit进行分页查询
- 格式:LIMIT 位置偏移量 , 数据条数
- 公式:LIMIT (pageNo-1) * pageSize, pageSize
pageNo表示第几页
使用分页的优点:约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率,如果我们知道返回结果只有1条,就可以可以使用LIMIT 1,告诉SELECT语句只需要返回一条记录即可,这样的好处就是SELECT不需要扫描全部的表字段,只需要检索到一条符合条件的记录返回即可
1,简单的分页查询
SELECT * FROM users_resulttable LIMIT 0,10;#查询第一页,一页十条数据 SELECT * FROM users_resulttable LIMIT 10,10;#查询第二页,一页十条数据
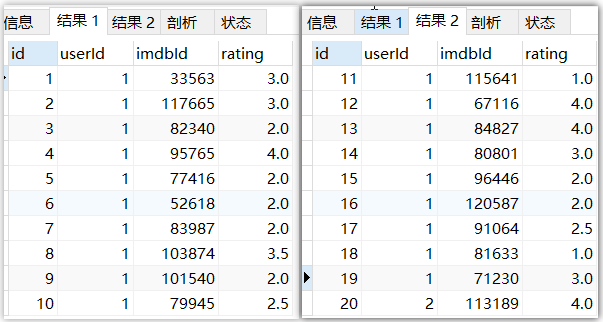
2,分页与WHERE,ORDER一起使用
使用时的顺序:
- WHERE
- ORDER
- LIMIT(放在最后面)
SELECT * FROM users_resulttable WHERE rating IN(4.0) ORDER BY imdbId LIMIT 0,5;
3,特殊格式
格式:LIMIT 数据条数
注:偏移量省略默认就为0
例:
#偏移量为0 SELECT * FROM users_resulttable LIMIT 3;
在MySQL8.0提供了"LIMIT 条数 OFFSET 偏移量"的格式
例:
SELECT * FROM users_resulttable LIMIT 3 OFFSET 1; #等价于 SELECT * FROM users_resulttable LIMIT 1,3;
二,分页拓展
在不同的DBMS中使用的关键字可能不同,在MySQL,PostgreSQL,MariaDB和SQLite中使用LIMIT关键字,而且都需要放在SELECT的最后面
1,如果是SQL Server和Access,需要使用TOP关键字,比如:
SELECT TOP 5 name,hp_max FROM heros;
2,如果是DB2,使用FETCH FIRST 5 ROWS ONLY关键字:
SELECT name,hp_max FROM heros FETCH FIRST 5 ROWS ONLY;
3,如果是Oracle,需要基于ROWNUM来统计计数(rownum为隐藏字段用于分页)
SELECT rownum,last_name,salary FROM employees WHERE rownum < 5;
三,分组查询
一,GROUP的使用
分组顾名思义就是将表按照字段进行分组
案例:现在有一个图书表,它有两个分类 ① 所属的馆类 ② 所属馆中的类别

① 查询每一个馆的图书数量(单字段分组)
SELECT category,COUNT(bookname) FROM test GROUP BY category;

② 查询每一个馆中每一类书籍的的数量(多字段分组)
SELECT category,category_class,COUNT(bookname) FROM test GROUP BY category,category_class; #category和category_class可以掉换位置,因为在同一类别的书必然在同一馆中 SELECT category,category_class,COUNT(bookname) FROM test GROUP BY category_class,category;

1,常出现的错误:SELECT中出现非函数的字段没有在Group声明中
#category_class字段是category的子集但没有在GROUP BY声明中,所以一个结果会出现一个结果覆盖了其他 SELECT category,category_class,COUNT(bookname) FROM test GROUP BY category;
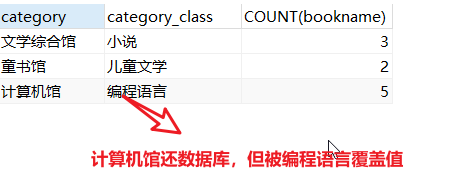
2,WITH ROLLUP的使用
GROUP BY + WITH ROLLUP作用:在查询出分组信息之后增加一条记录,该记录计算查询出所有记录的总和,即统计记录数量
SELECT category,COUNT(bookname) FROM test GROUP BY category WITH ROLLUP;

总结GROUP BY的几个注意事项:
- SELECT中出现非函数的字段必须声明在Group By中
- GROUP BY声明在FROM后面,WHERE后面,ORDER BY前面,LIMIT前面
- 当使用WITH ROLLUP时,不能同时使用ORDER BY进行结果排序,它们互相冲突
二,HAVING分组过滤
一,HAVING的使用
HAVING的作用:对GROUP BY分组后的数据进行进行条件过滤
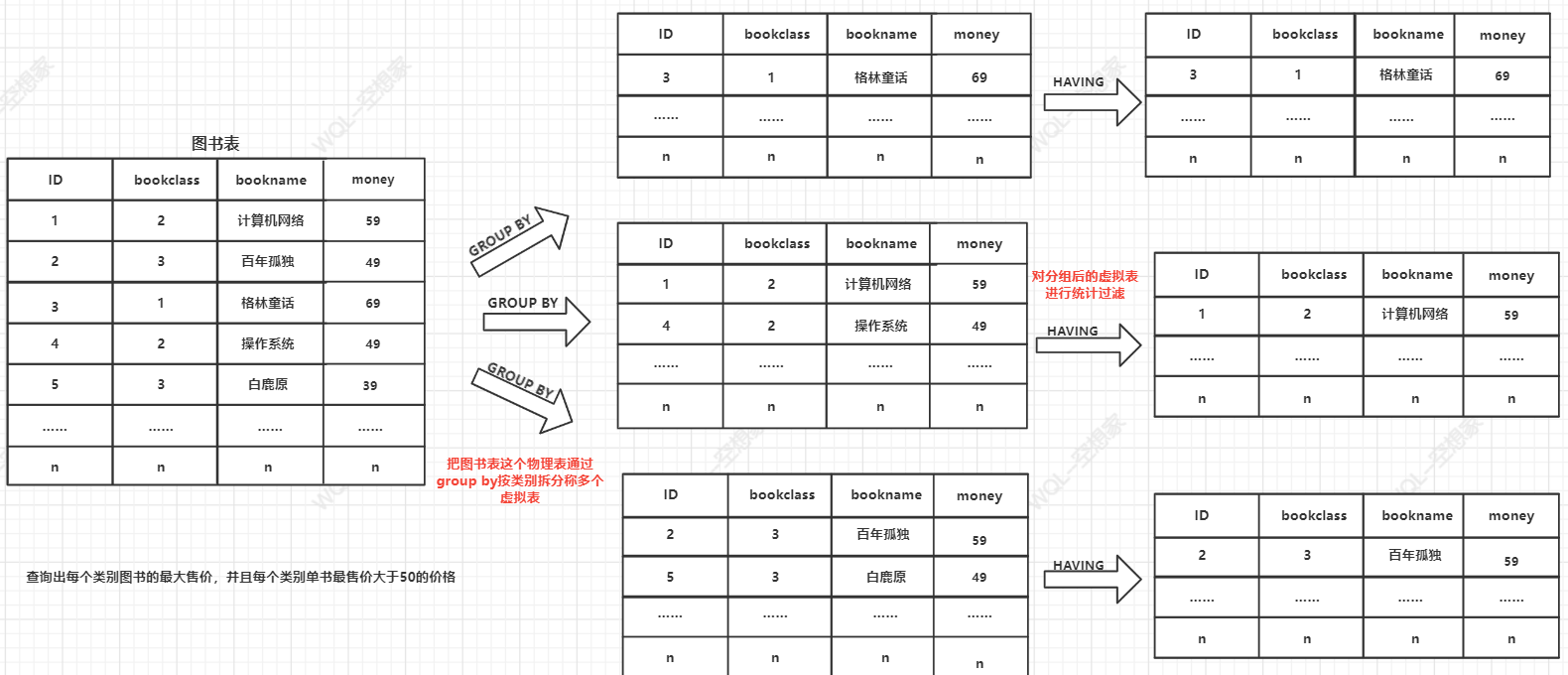
例1:查询每个图书类别中,单书的最大售价,并且这个最大售价大于50
分析:
- 图书类别需要分组
- 每一个类别需要找到最大单书售价,需要使用MAX()聚合函数找到最大值
- 最大值要大于50,需要在分组后的MAX()数据进行统计过滤
SELECT category_class,MAX(money) FROM test GROUP BY category_class HAVING MAX(money)>50;
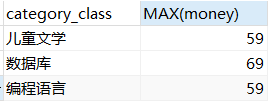
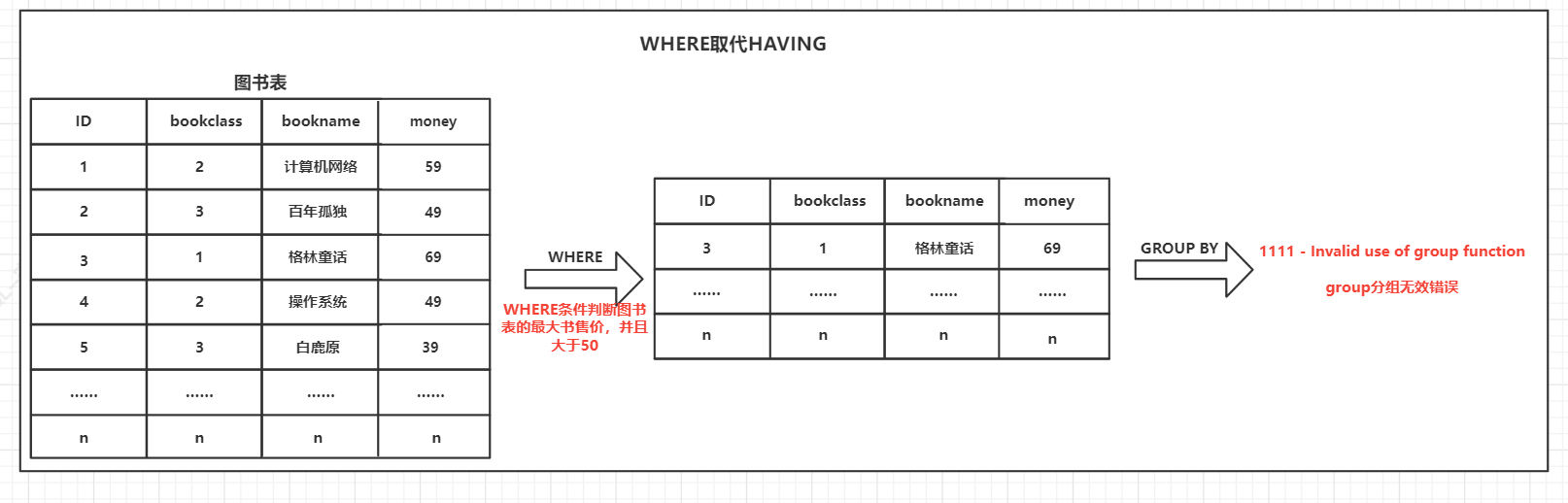
HAVING可以作为过滤统计,WHERE在使用中也是进行条件筛选,那么是否可以使用WHERE替代HAVING
例2:查询要求和例1一样,使用WHERE取代HAVING
SELECT category_class,MAX(money) FROM test WHERE MAX(money)>50 GROUP BY category_class;

原因:
- WHERE在GROUP前面执行,WHERE的输出作为GROUP分组的输入
- WHERE使用了聚合函数,聚合函数的特性是多个输入,一个输出,单输出GROUP是没有办法分组的
二,WHERE和HAVING的对比
主要区别:
- 执行优先级不同:where在分组之前进行过滤,不满足where条件就不会参与分组,而having是分组之后对结果进行过滤
- 判断条件不同:where不能对聚合函数进行判断,而having可以使用聚合函数
|
优点
|
缺点
|
|
|
WHERE
|
先筛选数据再进行关联,执行效率高
|
不能使用分组中的聚合函数进行筛选
|
|
HAVING
|
可以使用分组中的计算函数,并能对分组进行条件过滤
|
再分组后的结果集进行筛选,执行效率较低
|
开发中的选择:WHERE和HAVING的使用不是排斥的,我们可以在一个查询里面同时使用WHERE和HAVING
- 普通条件过滤使用WHERE
- 包含分组和聚合函数的条件滤使用HAVING
这样在即利用了WHERE条件的高效性,又发挥了HAVING可以使用包含分组聚合函数的优点,弥补了WHERE的短板
四,SELET的执行过程
一,SELECT语句的完整结构
SQL92版本的完整结构:
SELECT ……,……,……(存在聚合函数)
FROM ……,……,…
WHERE 多表连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ……,……,…
ORDER BY ……,……,…… [ASC/DESC]
LIMIT ……,……
SQL99版本的完整结构:
SELECT ……,……,……(存在聚合函数)
FROM ……,……,……
[LEFT/RIGTH] JOIN …… ON 多表连接条件
WHERE 不包含聚合函数的过滤条件
GROUP BY ……,……,……
ORDER BY ……,……,…… [ASC/DESC]
LIMIT ……,……
二,SELECT的执行过程
执行过程:① FROM --> ② ON --> ③ [LEFT,RIGHT] JOIN --> ④ WHERE --> ⑤ GROUP BY --> ⑥ HAVING -->⑦ SELECT --> ⑧ ORDER BY --> ⑨ LIMIT
在一个完整的执行过程中会产生很多的虚拟表,通过虚拟表进行下一阶段的操作
① SELECT是先执行FROM这一步,在这个阶段如果是多表联查,还会经历下面几个步骤:
- 首先先通过CROSS JOIN求笛卡尔积,相当于得到虚拟表vt(virtual table) 1-1
- 通过ON进行筛选,在虚拟表vt1-1的基础上进行筛选,得到虚拟表vt1-2
- 添加外部行,如果我们使用的是左连接,右连接或者全连接就会涉及到外部行,也就是在虚拟表vt1-2的基础上增加外部行,得到虚拟表vt1-3
如果操作的是两张以上的表则重复上面的步骤,直到所有表都被处理完成为止,这个过程得到的是我们的原始数据
② 当我们拿到查询的数据表原始数据,也就得到了vt1-3,就可以在此基础上再进行WHERE阶段,在这个阶段中,会根据vt1-3表的结果进行筛选过滤,得到虚拟表vt2
③ 然后进入第⑤和第⑥步,也就是GROUP和HAVING阶段,在这个阶段实际上是在虚拟表v2的基础上进行分组得到单个或者多个vt3表,在vt3表中再进行HAVING条件过滤得到vt4表
④ 当完成所有条件筛选之后,就进行筛选表中的字段,也就是进入了SELECT和DISTINCT阶段
- 首先再SELECT阶段提取想要的字段,得到中间虚拟表vt5
- 然后再进入DISTINCT阶段进行字段去重,得到虚拟表vt6
⑤ 提取到想要的字段之后,就可以按照指定的字段进行排序,也就是ORDER BY阶段,得到虚拟表vt7
⑥ 最后在vt7表的基础上去重指定行的记录,进入LIMIT阶段,得到最终结果vt8
在具体的select查询中,不一定都使用了所有关键字,如果没有相应的阶段就省略
Comments | NOTHING