




一,子查询的概念和分类
概念:子查询指一个查询语句嵌套在另一个查询语句内部,这个特性从MySQL4.1开始引入
数据库准备(SQL文件下载):https://www.aliyundrive.com/s/rAme3652tRE
主要用到employees和departments表
一,子查询的应用场景
SQL中子查询的使用大大增强了SELECT查询的能力,因为在很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较
子查询的应用场景:Select查询需要依赖于其他一个或多个查询的结果集
例如:查询比Daniel员工工资高的其他的员工
分析:
- 需要得到Daniel员工的工资
- 判断比这个工资高的其他员工
这里有一个问题:如何获取Daniel的工资并进行条件判断
针对这种情况有三种解决方案:
① 分步查询:使用多条语句实现(在Mybatis中提供了这个查询机制)
#1,先查询Daniel员工的工资 SELECT salary FROM employees WHERE first_name LIKE "Daniel"; #2,使用Daniel员工的工资作为条件进行判断(上一步结果为9000,我们这里是手动写,在Mybatis中可以直接做为参数传入) SELECT first_name,salary,job_id FROM employees WHERE salary>9000;
② 自连接查询:这种查询有特定的场景(所有的连接都在同一表中),因为工资获取,条件判断都只在员工表中所以可以用自连接
SELECT E.first_name,E.salary,E.job_id FROM employees E,employees M WHERE E.salary>M.salary AND M.first_name LIKE "Daniel";
③ 子查询:为这种查询场景而生的,实际开发中用得最广泛
SELECT first_name,salary,job_id FROM employees WHERE salary > (SELECT salary FROM employees WHERE first_name LIKE "Daniel");
三种方式结果都为:
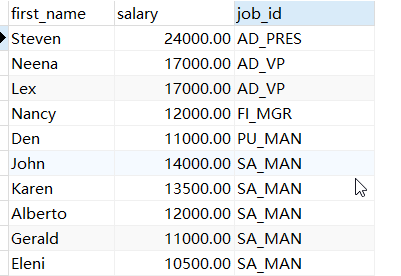
二,子查询的基本格式
子查询的基本语法结构:
SELECT select_list FROM table WHERE expr ooperator (SELECT select_list FROM table)
- 子查询(内查询)在主查询之前执行完成
- 子查询的结果被主查询(外查询)作为判断条件使用
注意事项:
- 子查询要写在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
三,子查询的分类
子查询的分类角度:
1,从子查询返回的结果条目数
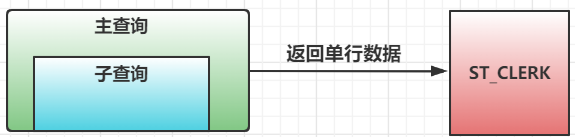
- 单行子查询:查询返回单行数据
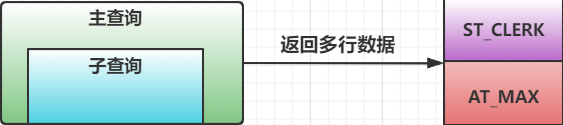
- 多行子查询:查询返回多行数据
2,子查询是否被执行多次
- 相关子查询:如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,没次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就是相关子查询
- 不相关子查询:子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行
二,单行子查询示例
单行的比较操作符:
|
操作符
|
含义
|
|
=
|
等于
|
|
>
|
大于
|
|
>=
|
大于或等于
|
|
<
|
小于
|
|
<=
|
小于或等于
|
|
<>
|
不等于
|
一,WHERE中的子查询
SELECT first_name,salary,job_id FROM employees WHERE salary >= (SELECT salary FROM employees WHERE employee_id IN(166))
示例2:返回job_id与166号员工相同,salary比188号员工多的员工信息
SELECT first_name,last_name,salary,job_id FROM employees WHERE job_id LIKE (SELECT job_id FROM employees WHERE employee_id IN(166)) AND salary > (SELECT salary FROM employees WHERE employee_id IN(188));
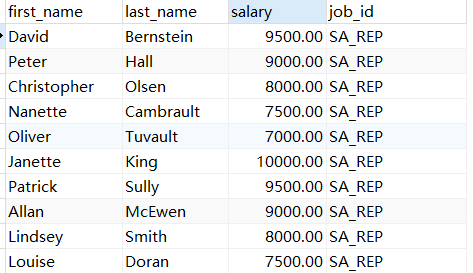
示例3:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name,salary,job_id FROM employees WHERE salary = (SELECT MIN(salary) FROM employees);
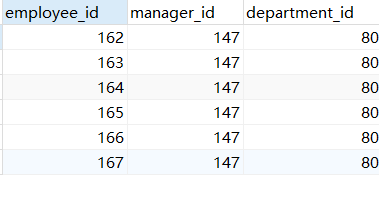
示例4:查询与166号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id
方式一:in进行分别判断
SELECT employee_id,manager_id,department_id FROM employees WHERE manager_id = (SELECT manager_id FROM employees WHERE employee_id IN(166)) AND department_id = (SELECT department_id FROM employees WHERE employee_id IN(166)) AND employee_id <> 166;
方式二:(字段1,字段2)做为一个整体
SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) = (SELECT manager_id,department_id FROM employees WHERE employee_id IN(166)) AND employee_id <> 166;
二,HAVING中的子查询
顺序:
- 首先执行子查询
- 向主查询中的HAVING子句返回结果
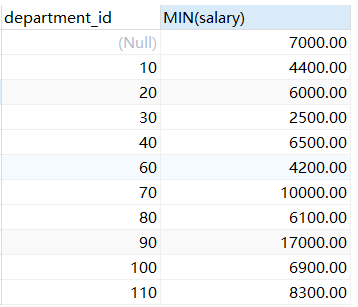
示例5:查询最低工资大于50号部门最低工资的部门id及其最低工资
SELECT department_id,MIN(salary) FROM employees GROUP BY department_id HAVING MIN(salary) >(SELECT MIN(salary) FROM employees WHERE department_id = 50);
三,CASE中的子查询
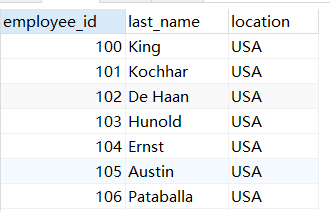
示例6:显示员工的employee_id,last_name和location,其中,若员工department_id与location_id为1800的department_id相同,则location为"canada",其余为"USA"
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN "canada" ELSE "USA" END "location" FROM employees;
四,单行子查询报错
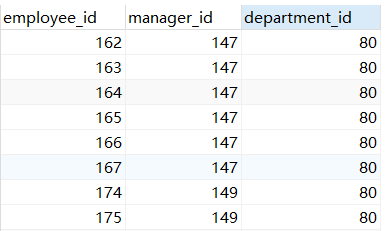
示例7:查询与166或177号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id
SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) = (SELECT manager_id,department_id FROM employees WHERE employee_id IN(166,177))
子查询返回了两行数据(166和177),=本身是单行操作符,(manager_id,department_id)对应两行的值,所以会报错
> Subquery returns more than 1 row #子查询返回多于一行的数据 > 时间: 0s
这种情况就需要使用多行子查询解决
三,多行子查询示例
多行子查询也称集合比较子查询:
- 子查询返回多行
- 使用多行比较操作符
|
操作符
|
含义
|
|
IN
|
等于列表中的任意一个
|
|
ANY
|
需要和单行比较操作符一起使用,和子查询返回的某一个值比较
|
|
ALL
|
需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
|
SOME
|
实际上是ANY的别名,作用相同,一般常使用ANY
|
示例1:解决上述单行子查询报错问题(把等号改为IN即可)
SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) IN (SELECT manager_id,department_id FROM employees WHERE employee_id IN(166,177))
一,ANY和ALL的理解使用
- ANY:任一值
- ALL:所有值
示例2:查询比job_id为"IT_PROG"部门中任一员工工资低的其他员工信息(员工号,姓名,job_id,salary)
SELECT employee_id,first_name,salary,job_id FROM employees WHERE salary < ANY(SELECT salary FROM employees WHERE job_id = "IT_PROG");
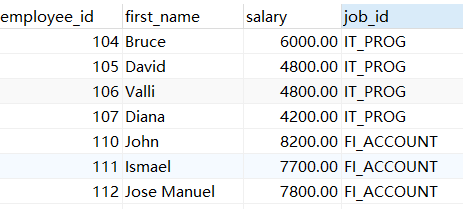
示例3:查询比job_id为"IT_PROG"部门中所有员工工资低的其他员工信息(员工号,姓名,job_id,salary)
SELECT employee_id,first_name,salary,job_id FROM employees WHERE salary < ALL(SELECT salary FROM employees WHERE job_id = "IT_PROG");
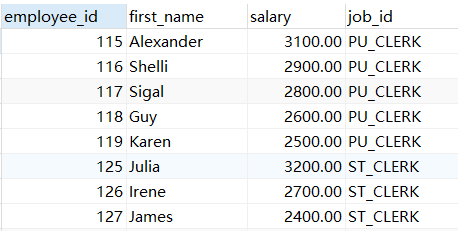
示例4:查询平均工资最高的部门id(有很多干货)
1,聚合函数嵌套错误
#首先要查询出每个部门的平均工资,再对这个工资列表进行排序 SELECT MAX(expr)AVG(salary)) FROM employees GROUP BY department_id;
结果报错:

注:在Mysql中聚合函数无法嵌套,但Oracle中是可以的,所以使用时需要区分
方法一:将查询的各个部门的平均工资列表做为一张表进行判断
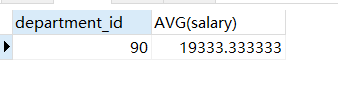
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id HAVING AVG(salary) = ( SELECT MAX(maxavgslary) FROM (SELECT AVG(salary) maxavgslary FROM employees GROUP BY department_id) avgbm )
这种方式叫做from型子查询:子查询是做为FROM的一部分,子查询要用()括起来,并且要给这个子查询取别名,把它当成一张"临时虚拟表"来使用
方法二:使用ALL
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id HAVING AVG(salary) >= ALL( SELECT AVG(salary) maxavgslary FROM employees GROUP BY department_id )
结果都为:
空值问题:
- 单行子查询中只要有null参与判断结果都为空
- 多行子查询中,需要判断null是不是查询想要的,假如不是就排除掉,否则会全部为null,如:not in (有null,其他真实数据),那么这条结果就是null,因为其他数和它判断就是null
四,相关子查询示例
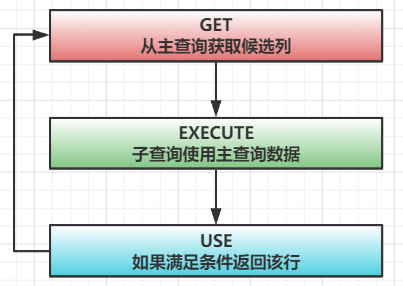
在之前的单行和多行子查询都属于不相关子查询,因为主查询和子查询之间没有关系,子查询仅仅是为主查询提供客观的唯一条件,而相关子查询就和之前示例有很大不同
相关子查询(关联子查询)的含义:子查询的执行依赖于外部查询,因此每执行一次外部查询,子查询都要重新计算一次
注:
- 在非关联查询中主查询使用子查询的数据集,而子查询静态单独存在
- 关联查询子查询使用主查询的列,主查询依然使用子查询的结果集,子查询是动态存在的
- 在SELECT语句中除了ORDER BY和LIMIT后面不能接子查询,其他语句都可以使用子查询
一,相关子查询示例
示例1:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id信息
方式一:使用多表联查解决,将各部门的平均工资数据作为表与员工表做连接
SELECT EM.last_name,EM.salary,EM.department_id FROM employees EM, (SELECT department_id,AVG(salary) avgsalary FROM employees WHERE department_id IS NOT NULL GROUP BY department_id) DM WHERE EM.department_id = DM.department_id AND EM.salary > DM.avgsalary;
这种方式叫做from型子查询:子查询是做为FROM的一部分,子查询要用()括起来,并且要给这个子查询取别名,把它当成一张"临时虚拟表"来使用(重点)
方式二:使用子查询解决(这种场景的通用解决方法)
SELECT last_name,salary,department_id FROM employees EM WHERE salary > ( SELECT AVG(salary) FROM employees RM WHERE RM.department_id=EM.department_id )
子查询RM绑定了主查询EM的department_id,每一次子查询执行时都需要获取主查询的department_id
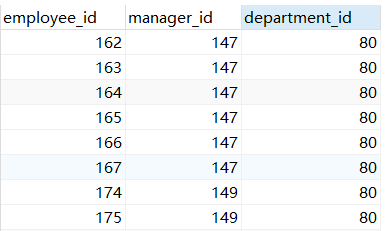
示例2:查询员工的id,salary按照department_name排序
SELECT employee_id,salary FROM employees EM ORDER BY (SELECT department_name FROM departments DP WHERE DP.department_id = EM.department_id);
示例3:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
SELECT employee_id,last_name,job_id FROM employees EM WHERE (SELECT COUNT(EM.employee_id) FROM job_history JH WHERE EM.employee_id = JH.employee_id) >= 2;

二,EXISTS与NOT EXISTS关键字
关联子查询通常也会和EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行
EXISTS:
- 如果在子查询中不存在满足条件的行,返回FALSE,继续在子查询中查找
- 如果在子查询中存在满足条件的行,返回TRU,不在子查询中继续查找
NOT EXISTS:功能与EXITS相反,其他一样
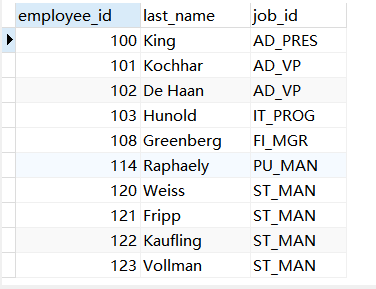
示例4:查询公司管理者的employee_id,last_name,job_id,department_id信息
方式一:自连接查询
SELECT DISTINCT EM.employee_id,EM.last_name,EM.job_id,EM.department_id FROM employees EM,employees RM WHERE EM.employee_id=RM.manager_id;
方式二:子查询通用方式
SELECT employee_id,last_name,job_id FROM employees WHERE employee_id IN( SELECT DISTINCT manager_id FROM employees WHERE manager_id IS NOT NULL);
方式三:FROM型子查询
SELECT DISTINCT EM.employee_id,EM.last_name,EM.job_id FROM employees EM,( SELECT manager_id,employee_id FROM employees WHERE manager_id IS NOT NULL) RM WHERE EM.employee_id = RM.manager_id;
方式四:EXISTS
SELECT DISTINCT EM.employee_id,EM.last_name,EM.job_id FROM employees EM WHERE EXISTS( SELECT * FROM employees RM WHERE EM.employee_id = RM.manager_id )
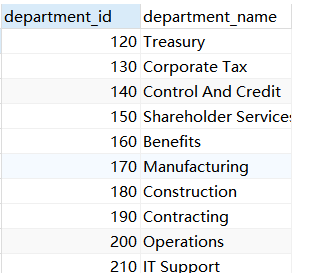
示例5:查询departments表中不存在于employees表中的部门的department_id和department_name
方式一:外连接查询(左右随意,注意顺序即可),以右连接为例
SELECT DP.department_id,DP.department_name FROM employees EM RIGHT JOIN departments DP ON EM.department_id = DP.department_id WHERE EM.department_id IS NULL;
方式二:NOT EXISTS
SELECT DP.department_id,DP.department_name FROM departments DP WHERE NOT EXISTS( SELECT * FROM employees EM WHERE DP.department_id = EM.department_id )
其他方式省略……
三,拓展内容
① 相关更新:使用相关子查询依据一个表中的数据更新另一个表的数据
示例6:在employees中增加一个department_name字段,数据为员工对应的部门
#1,增加一个department_name字段 ALTER TABLE employees ADD (department_name VARCHAR(14)) #2,相关更新 UPDATE employees e SET department_name = ( SELECT department_name FROM )

② 相关删除:使用相关子查询依据一个表中的数据删除另一个表的数据
示例7:删除employees中,其与emp_history表都有的数据
DELETE FROM employees EM WHERE employee_id in( SELECT employee_id FROM job_history JH WHERE JH.employee_id = EM.employee_id );
子查询和自连接查询的选择:(重点)
- 假如自连接可以解决问题,一般建议使用自连接查询,因为许多DBMS的处理过程中,自连接的处理速度要比子查询要快很多
- 子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表示条件判断,因此在大部分DBMS中都对自连接处理进行了优化
注:很多DBMS中,把子查询拆解后发现可以用多表查询处理,就会在底层转换成多表查询处理
Comments | 1 条评论
Warning: Undefined variable $m in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
Warning: Trying to access array offset on value of type null in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
Deprecated: stripslashes(): Passing null to parameter #1 ($string) of type string is deprecated in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
Warning: Undefined variable $m in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
Warning: Trying to access array offset on value of type null in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
Deprecated: stripslashes(): Passing null to parameter #1 ($string) of type string is deprecated in /www/wwwroot/wql_luoqin_ltd/wp-content/themes/Sakura/functions.php on line 1767
66666