




1. Elastic Stack简介
Elastic Stack的前身为ELK
ELK它是三款软件的总称:
- Elasticsearch
- Logstash
- Kibana
ELK在发展过程中,又有新组件Beats加入,所以新组件加入就把原来的ELK改成Elastic Stack新名字
Elastic Stack的组成:
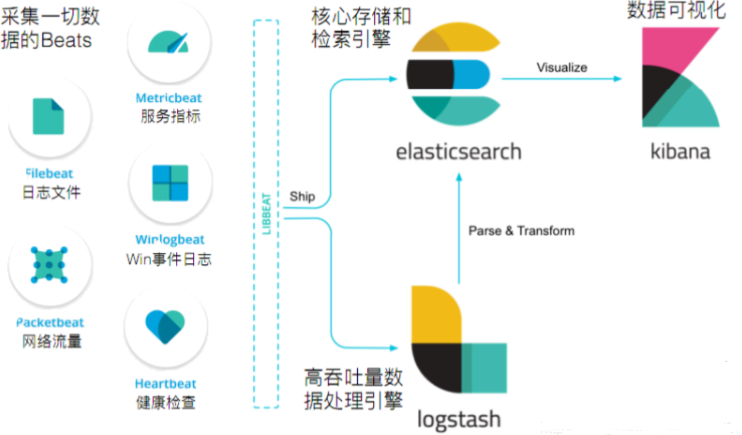
1)Elasticsearch
Elasticsearch基于java,是开源分布式搜索引擎,它的特点有:分布式、零配置、自动发现、索引自动分片、索引、索引副本机制、RestFul风格接口、多数据源、自动搜索等
2)Logstash
Logstash基于java,是一个开源的用于收集、分析和存储日志的工具
3)Kibana
Kibana基于nodejs,也是一个开源的免费的工具,Kibana可以为Logstash和ElasticSearch提供的日志分析友好的Web界面,可以汇总、分析和搜索重要数据日志
4)Beats
Beats是elastic公司开源的一款采集系统监控数据的代理agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动
Beats由如下组成:
- Packetbeat:是一个网络数据包分析器,用于监控、收集网络流量信息,Packetbeat嗅探服务器之间的流量,解析应用层协议,并关联到消息的处理,其支 持ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache等协议
- Filebeat:用于监控、收集服务器日志文件,其已取代 logstash forwarder;
- Metricbeat:可定期获取外部系统的监控指标信息,其可以监控、收集 Apache、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务;
- Winlogbeat:用于监控、收集Windows系统的日志信息;
2. ES简介
Elasticsearch简称ES,它是一个开源的高拓展的分布式全文搜索引擎,是整个Elastic stack技术栈的核心
ES是基于Apache Lucene构建的开源搜索引擎,是当前最流行的企业级搜索引擎。Lucene是被认为是迄今为止性能最好的一款开源引擎工具包,但是Lucene的API相对复杂,需要深厚的搜索理论,很难集成道实际应用中去。ES采用java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的RestFul API,开放相关的搜索功能,从而避免Lucene的复杂性
注:Elasticsearch本质上是对Lucene的功能封装,将Lunene的功能调用简化
全文检索的含义:是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程
全文检索以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标
- 只处理文本,不处理语义
- 搜索英文不区分大小写
- 结果列表有相关排序
3. ES数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,它有四大存储数据的概念
- Index:索引
- Type:类型
- Documents:文档
- Fields:字段
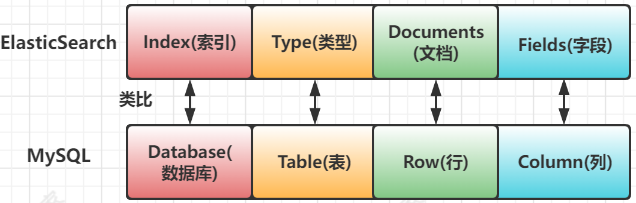
ES里面的Index可以看做一个库,而Types相当于表,Documents则相当于表的行,这里Types的概念已经逐渐被弱化,Elasticsearch6.x中,一个Index下已经只能包含一个type,Elasticsearch7.x中type概念已经被删除
ES使用的倒排索引,MySQL使用的是正排索引:
1)MySQL正排索
|
id
|
container
|
|
100
|
lala shili
|
|
101
|
lala wangwu
|
如果在这种结构数据做内容查询,需要进行SQL的模糊查询,每条数据的内容都需要遍历匹配,及耗时间,而且大小写、词态等都会影响到准确性
2)Elasticsearch倒排索引
| keyword | id |
| lala | 100,101 |
| shili | 100 |
通过内容关键字绑定主键id,再通过主键查找内容
注:在关系性数据库中索引是为优化查询效率而设置的结构,不使用索引也能查询只是相对较慢;Elasticsearch是全文检索引擎,索引就是最重要的部分,所以淡化了表的概念
4. ES的三大核心概念
ES的三个核心:
- 索引(Index)
- 映射(Mapping)
- 文档(Document)
1)索引
一个索引就是一个拥有相似特征的文档的集合。比如说,你可以有一个商品数据的索引、一个订单数据的索引、一个用户数据的索引。一个索引由一个名字来标识(必须是全部小写的字母组成),并且当我们要对整个索引中的文档进行索引的搜索、更新和删除时,都要使用这个名字
2)映射
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动的创建mapping,也可以手动创建mapping。mapping中主要包含字段名、字段类型
3)文档
文档是索引中存储的一条条数据,一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示
为了更方便的理解用关系性数据类比:
- 索引 <--> 数据库
- 映射 <--> 字段,字段类型等声明
- 文档 <--> 具体的数据
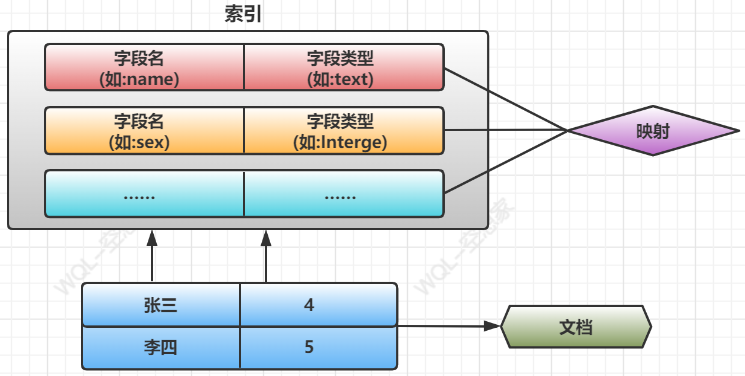
索引和映射是一个统一体,就是关系性数据库建表时需要指定字段、类型等,但ES不需要强制性指定映射,默认会有映射,但使用时最好指定映射
Comments | NOTHING