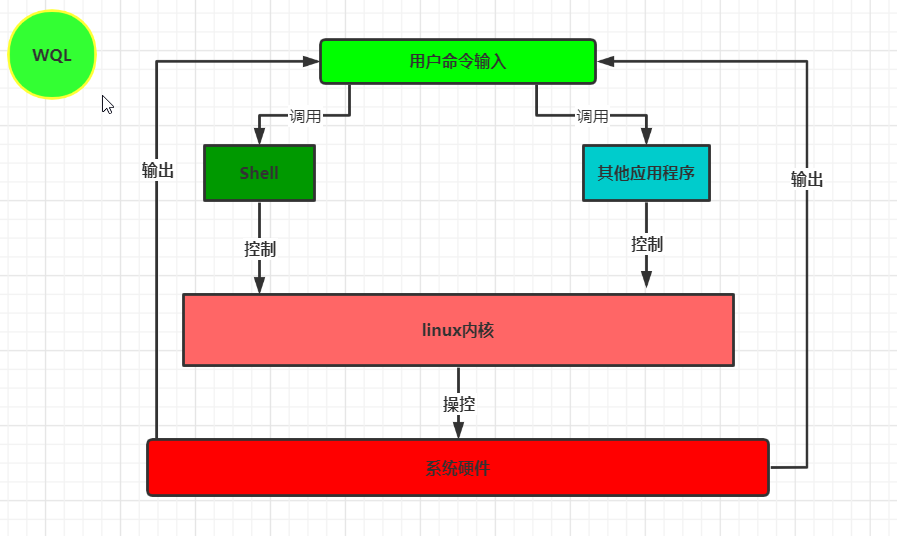
Shell(壳),shell是用户和系统沟通的桥梁
用户命令 -> shell解析-> Linux内核执行 -> 控制系统硬件 ->输出结果

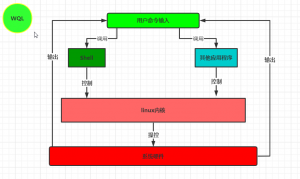
注:shell是一个语法解析器,不同的shell命令语法也不同
shell的分类:
1,/bin/bash:现在Linux发行版本都在用的一个shell类型,包涵的功能涵盖了shell的所有功能(重点)
2,/bin/sh:/bin/bash的快捷方式,内部有一个软连接

3,/bin/dash:小巧高效但功能相对较少
4,/bin/csh:类c语言风格的shell,具有许多特性,但功能相对较少
5,/bin/tcsh:是csh的增强版,完全兼容csh
6,/bin/nologin:非交互式的,不能登录操作系统
bash的特性:每一种shell都有自己独特的语法和命令,这就是特性
bash是弱类型的编程语言,不严格区分数据类型,意味把所有数据统统当作字符串处理;
1,定义别名:alias 变量=‘命令或者其他’ (全局配置文件/etc/bashrc)
2,历史命令查看:shell进程会保存其会话中用户曾经执行过的命令;命令通过其“历史文件”来持久保存此前执行过的命令;每个用户都有其自己专用的历史文件
HISTSIZE:shell进程的缓冲区保留的历史命令的条数(默认1000)
HISTFILESIZE:命令历史文件可保存的历史命令的条数(默认1000)
3,命令补全功能:TAB键
4,通配符:?,*
一,shell编程的小工具
编程小工具的积累,可以在写shell脚本时获得极大的好处
一,grep
grep是一个文本查询工具,把输入流一行一行的处理,对文本进行匹配和分析,当不能对文本进行编辑
格式:grep 选项 “匹配模式” 路径(文本文件或者文件夹)
grep两个通配符:
^字符串:以什么开头
字符串$:以什么结尾
-i:忽略大小写
-n:显示匹配内容的行号

-v:取反,输出不匹配的所有行

-c:统计匹配到的次数

-r:逐级从目录下查找所有文件进行匹配(假如路径是文件,他会递归匹配文件下的所有文本文件)

-l:显示所有匹配文本的文件名(列出符合条件的文本文件名称)
-L:显示所有匹配文本的文件名,与-l相反

-e:所有正则匹配(默认)
-E:使用拓展正则匹配

-A:输出匹配行的前面多少行
-B:输出匹配文本的后面多少行
-C:输出匹配文本的前后多少行

重点:正则表达式
正则表达式是任何编程语言都会用到的一套字符匹配规则
正则按用途主要分四类:
1,字符类:限定出现的字符
2,数量限定符:限定出现字符的数量
3,位置限定符:限定出现字符的位置
4,特殊字符:排除上述三类就是特殊字符
字符类:
1,.:任意单个字符
2,[]:匹配括号内的字符
3,-:字符范围 如:[a-z] 从a到z
4,^:再括号内使用,代表非 [^a] 除a以外的任意字符
数量限定符:
1,?:匹配零或者一次
2,+:匹配一次或者多次
3,* :匹配零或者多次
4,{n,m}:最少匹配n次,最大匹配m次
5,{n,}:至少匹配n次
6,{,m}:最多匹配m次
7,{n}:匹配n次
位置限定符:
^:以什么字符开始
$:以什么字符结束
特殊字符:
():分组
|:连接两个字表达式,或的意思
\:转义
在shell脚本中拓展正则:
在基本正则下,{},/,|,() 都会被当做普通字符解析,需要在用\进行转义,当在拓展正则下支持这些字符
二,tee
文件之间的输入追加可以用重定向来解决,也可以靠命令,
格式:tee 选项 文件名
Linux tee命令用于读取标准输入的数据,并将其内容输出成文件。
没有管道的话,tee要手动输入文件内容
-a:以追加的方式(默认是覆盖)
-i:忽l终断信号(正常退出要ctrl+c,这个加上就只能关闭窗口)

注:关于管道,tee和重定向是有区别的,
echo “wql” > yu :内容不会打印输出
echo "wql" | tee filename :内容会被打印输出

三,cut
cut是列截取命令,用来列的截取
格式:cut 选项 文件名
选项:
-d:自定义分割符
-f:选区
选区的方式:
源数据格式:

-f n:输出第n个选区

-f n,m:输出第n和m选区

-f n-m:输出第n到m的选区

-f n- :输出n开始的所有选区

-f -n :输出以n结尾的所有选区

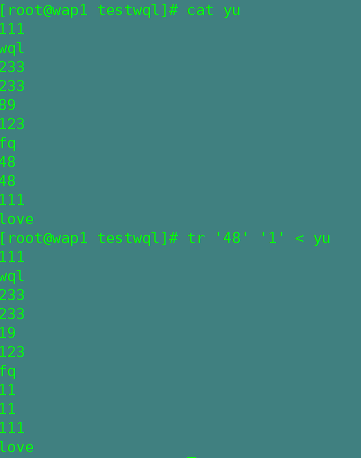
四,tr
ctr对字符串进行替换,删除操作
三种格式:
格式1:commands | tr ‘string1’ ‘string2’
对查找string1的内容,并把它替换成string2
格式2:tr ‘string1’‘string2’ < file文件(标准输入)
作用和格式1一样,只是输入方式不一样
格式3:tr 选项 ‘string’< file
作用进行删除操作
选项:-d :删除匹配的字符串
-s:删除重复出现的字符序列
注:匹配方式可以有正则,替换只单个字符替换 如:tr ‘wql’ ‘fq ’ 之后替换成 ‘fqq’
替换操作:
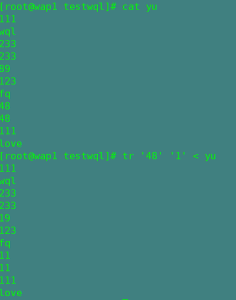
删除操作:

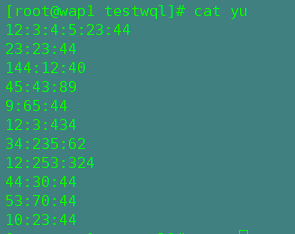
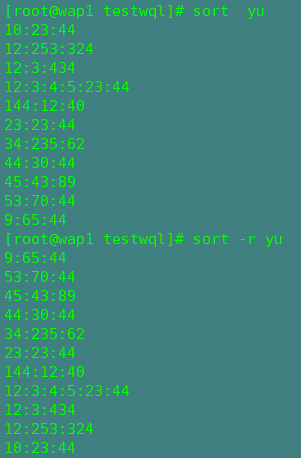
五,sort
sort是文件的排序命令,它以文件的行为单位,从首行开始,依次按ACISS来比较
格式:sort 选项 文件
源数据:
-r:降序排序(默认是升序排序)
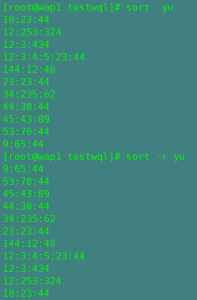
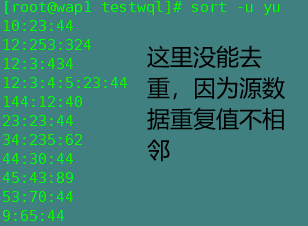
-u:去重
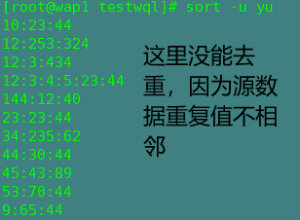
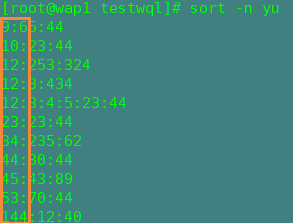
-n:以数字排序(默认是按字符的ASICC码排序)
-t:指定分割符
-k:指定要选取的分割列
-tk和cut列截取一样

-o:将排列后的文件输出到指定文件
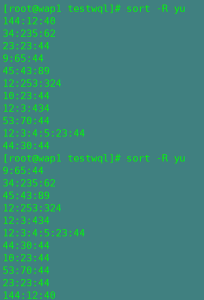
-R:随机排序,每次输出不同的值
六,uniq
uniq 文件去重(uniq去重与sort -u不一样它去重只能去重相邻的重复值)
格式 : uniq 选项 文件名
选项:
无选项:
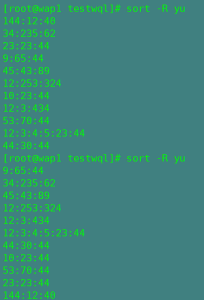
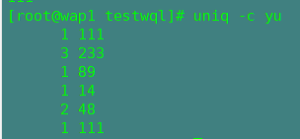
-c:统计重复值出现的次数
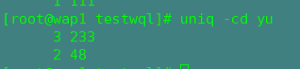
-d:仅显示重复值出现的行列
七,diff
文件的比较
diff 选项 文件1 文件2
源文件内容:

diff的显示格式:
默认格式:

标记符:
<:代表文件1
>:代表文件2
---:分隔符(无意义)
c:修改
a:添加
d:删除
数字表示第几行
解释:
2c2:表示修改文件1的第2行,可以和文件2的第2行匹配
<233 >wql:把233改成wql
6c6,7:表示修改文件1的第6行,可以和文件2的6,7行匹配
<14 >123 >fq:把14改成123和fq
上下文格式:用-c表示

标识符:
!:修改
+:添加
-:删除
合并显示:-u表示,在一个文件中进行修改(常用这个)

解释:这些操作全都在文件1中执行
-233:删除233
+wql:添加wql
-14:删除14
……
常用选项:
-i:忽略大小写
-B:不检查空白行
-b:不检查空格
-q:比较目录的不同
diff和patch补丁工具:
patch可以把diff的不同,形成补丁,对源文件进行修改,让文件相同
把diff的输出内容重定向进后缀名为patch的文件中,
patch 格式:patch 文件 patch文件

二,变量
一,变量的定义方式:
1,直接定义:变量名=变量值
2,交互式定义:
a, read - p '提示' 变量名

b,read -p '提示' 变量名 < 文件 (不要交互,值来自于文件)

二,变量的读取方式:
1,$变量名
2,${变量名}
三,变量的删除:
unset 变量(不要带$)
 $和${}的区别:
$和${}的区别:
${}可以对字符串进行分割,$就不行

命令的返回值赋值给参数:
1,`命令`:用反斜杠
2,${命令}:用$()

四,变量的分类:
env:查看环境变量
set:查看全部变量
1,本地变量:就是普通的变量
2,环境变量:export 本地变量 (临时设置,且只有当前用户有效)

3,全局变量:在系统配置文件配置环境变量
系统配置文件:
1,全局配置:/etc/profile , /etc/bashrc
/etc/profile:为每一个用户设置,每一个用户登录都会读取profile配置文件(作用:设置环境变量,运行命令或者脚本)
/etc/bashrc:每一个运行bashshell的用户,都会读取bashrc,都是为每一个用户设置(作用:定义别名,设置本地变量)
2,个人配置:~/.bashrc,~/.bash_profile
~/.bashrc: 当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件。
~/.bash_profile : 该文件包含专用于你的bashshell的bash信息,当登录时以及每次打开新的shell时,该文件被读取。
格式:export PATH=$PATH:$变量名
4,系统变量:系统自带变量
$?:查看上条命令是否正确执行,0表示正常执行(常用)
$0-9:位置参数
$0:获取当前执行的shell脚本的文件名
$$: 获取当前shell的进程号(PID)
$!: 执行上一个指令的PID
$#:统计参数个数
单引号和双引号字符串的区别:' '内部不能引用变量(如果有只会当字符串处理)," "可以引用变量
三,流程控制
一,四则运算
Linux四则运算的四种格式:
1,$(())
2,$[]
3,expr
4,let
+(加) -(减) *(乘) /(除) %(取余)
注:在这四种模式中只能对整数进行判断,浮点数不能计算(bc计算浮点数)
$(()):

$[]:

expr:
expr不仅可以进行数字操作,也可以进行字符串操作

let:
格式:let 变量 = 表达式

二,条件判断
条件判断和if流程控制语句差不多,shell的条件判断也可以代替if语句
条件判断的四种格式:
1,[判断表达式]
2,[[判断表达式]]
3,test 判断表达式
命令间的逻辑关系:
&&:前面一个为真才执行后面的语句
||:前面一个为假才执行后面的语句
数值判断:
-eq:判断数值是否相等
-ne:判断两个数是否不等
-gt:判断第一个数是否大于第二个数
-lt:判断第一个数是否小于第二个数
-ge:大于或者等于
-le:小于或者等于
字符串的判断:
==:判断两字符串是否相对等(=两边要空格)
!=:不等
>:大于 (ASICC判断大小)
<:小于
文件的判断:
-e :判断文件是否存在(普通文件和目录)
-f :判断文件是否为普通文件
-d:判断指定文件是否为目录
-z:判断文件是否为空
-a:判断文件是否不空
-r:判断文件是否可都
-w:判断文件是否可写
-x:判断文件是否可执行
类c风格的比较:
类c风格和上面三种判断不一样,它没有刚才的数值判断,字符串判断,文件判断的属性
=:赋值
==:判断是否相等(和其他三种不一样,数值和字符串都能用)
!=:不相等
>=:大于等于
<=:小于等于
……
格式:((判断语句))
[]和[[]]的区别:
1,[]对空值不能判断,[[]]可以判断
2,&&逻辑判断在[]里面不能用,[[]]能用
if流程控制
if流程控制依赖于shell的条件判断,if可以用用条件判断来代替
条件判断的格式在if中通用
单分支格式:if 条件判断;then 操作语句 fi (类似于条件判断:[] && [])

多分支格式:if 条件判断; then 操作语句 elif 判断条件; then 操作语句 …… else 操作语句 fi (类似于条件判断:[] && [[]] || [] )

三,循环
一,for循环
for循环有三种结构:一种是列表for循环,第二种是不带列表for循环。第三种是类C风格的for循环。
一,列表for循环
#!/bin/bash
for varible1 in {1..5}
#for varible1 in 1 2 3 4 5
echo "Hello, Welcome $varible1 times "
do和done之间的命令称为循环体,执行次数和list列表中常数或字符串的个数相同。for循环,首先将in后list列表的第一个常数或字符串赋值给循环变量,然后执行循环体,以此执行list,最后执行done命令后的命令序列。
Sheel支持列表for循环使用略写的计数方式,1~5的范围用{1..5}表示(大括号不能去掉,否则会当作一个字符串处理)。
Sheel中还支持按规定的步数进行跳跃的方式实现列表for循环,例如计算1~100内所有的奇数之和。
通过i的按步数2不断递增,计算sum值为2500。同样可以使用seq命令实现按2递增来计算1~100内的所有奇数之和,
for i in $(seq 1 2 100),seq表示起始数为1,跳跃的步数为2,结束条件值为100。
二,非列表for循环
由用户制定参数和参数的个数,与上述的for循环列表参数功能相同。#!/bin/bash
echo "number of arguments is $#"
echo "What you input is: "
done
比上述代码少了$@参数列表,$*参数字符串
三,c语言风格的for循环
#!bin/bash
for((integer=1;integer<=5;integer++))
do
echo ${integer}
done
for中第一个表达式(integer = 1)是循环变量赋初值的语句,第二个表达式(integer <= 5)决定是否进行循环的表达式,退出状态为非0时将退出for循环执行done后的命令(与C中的for循环条件是刚好相反的)。第三个表达式(integer++)用于改变循环变量的语句。
Sheel中不运行使用非整数类型的数作为循环变量,循环条件被忽略则默认的退出状态是0,for((;;))为死循环。
类C的for循环计算1~100内所有的奇数之和。
二,while循环
也称为前测试循环语句,重复次数是利用一个条件来控制是否继续重复执行这个语句。为了避免死循环,必须保证循环体中包含循环出口条件即表达式存在退出状态为非0的情况。
格式:while 条件判断 do 执行语句 done
四,Sed流编辑器
sed和vim都属于文本编辑器,但vim是交互式的,sed是非交互式,sed适合文件批处理编辑的使用,它通过模式匹配和指令,可以大批量修改文件
sed修改文件在内部的执行的操作:
1,一次从文件中读取一行数据
2,根据编辑器提供的匹配模式和命令匹配数据
3,修改模式空间中的数据
4,命令行打印 或者 从模式空间直接输入进文件

一行一行的读取编辑

sed的命令格式: sed [option] ‘[pattern/common]’ file
sed [选项] ‘[匹配模式/命令]’ 元文件
一,set的选项:
无选项:sed无任何选项参数时,默认把全部文本输出 例:如果无选项,匹配数据会被打印两次

-n:只匹配打印符合匹配原则的行,避免了多次打印

-e:可以多次交互式匹配,格式:-e 匹配模式 ,可以多个匹配模式匹配

-f:把匹配规则和命令保存到指定文件中,通过文件中的指令去匹配数据
格式:-f 命令文件 元文件

-i:之前都是在对模式空间(缓冲区)中的数据进行修改再打印输出,-i把模式空间中的数据直接写回元文件

-r:支持正则拓展元字符(正则再讲)
二,sed的模式匹配(pattern)
源文件:

sed的匹配模式有很多种写法:
1,'起始行号,终止行号 '

2,'起始行号,+数字':终止行号是起始行号加你数字的和

3,'/匹配原则/行为':这是我们常用的写法

4,'行号,/匹配原则/行为':从开始行号到符合数据元素的那一行

5,'/匹配原则/行为,行号':从符合匹配原则的行开始到指定的行结束

注:这几种写法最常用的还是第3种写法
三,sed的行为
sed的行为主要分为增删改查,与模式匹配混合使用
查询:
p:打印符合匹配规则的数据

删除:
d:删除符合匹配规则的数据

注:-n是只打印符合匹配规则的行,与查询依赖,删除加-n数据不会显示,最好是无选项
修改:
修改和其他的写法格式不同
格式:
s/匹配规则/替换字符/属性
属性:
i:不区分大小写
g:全部修改替换,不加g,默认只替换一个

修改的分组概念:
&:代表匹配到的数据
/1:匹配数据要用括号,代表第一个括号内的数据
增加:
a:行后追加
格式: /''/a 追加内容

i:行前追加
格式和a一样

r:把指定文件内容追加到匹配行的行后
格式:/''/r 文件路径

w:把匹配内容写入到其他文件中
格式和r一样

五,awk文件数据分析
awk是独立于Linux的一种编程语言,它主要用于处理Linux/unix的文本和数据,数据可以来自于标准输入,一个或多个文件,其他命令输出
awk处理数据和文件的方式:和sed类似,它将文件一行一行读取,并对每一行数据进行格式匹配和其他操作,(和sed不同它不可以直接对源文件进行修改)
格式:awk 选项 ‘命令部分’文件名
选项:
-F:定义列分割符 (通过分割符划分域)
-v:定义变量
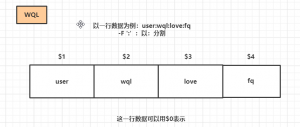
awk内置通配符:$0表示当前一行,$1~$9代表不同的域
命令部分的多种格式:
一,BEGIN……END
BEGIN...END:BEGIN{开始语句} {awk语句} END{结束语句}

二,地址定位
1,NR:NR条件{awk语句},支持==,<=,>=

2,/起始正则/,/终止正则/{awk语句}

内置变量:
NR:指定行号
NF:浏览域的个数,也可以指定最后一个域
FILENAME:浏览的文件名

FNR:浏览文件的行号

FS:设置域的分隔符,等价于-F

OFS:设置输出域的分隔符

RS:控制行的输入分隔符(默认/n换行符为分隔符)

ORS:控制行的输出分隔符(默认也是\n)

打印:print和printf
print是awk的内置变量,printf是类C语言风格支持格式化输出
主要讲printf的格式化输出:
格式化输出的占为符:
%s:字符类型
%d:数值类型
-:表示左对齐(默认右对齐)
格式:% 字节大小 s(d)

变量的定义和使用:
-v 变量名=变量值

注:在awk语句中变量不能用$符,直接写变量名
awk中的if判断:
awk的if和shell中的if不一样,这是awk语言自带的if
格式:
单分支:if(条件判断){执行语句} else{执行语句}
多分支:if(条件判断){执行语句} else if{执行语句} else if{执行语句} ……else{}

awk的for循环:
awk的循环也是类C语言风格的
格式:for(i=;i<=;i++){}












Comments | 4 条评论
牛逼??????
宝剑锋从磨砺出,梅花香自苦寒来
莲子清如水,莲心彻底红??
@匿名 ???
努力